真·五彩斑斓的黑!耕升GeForce RTX 5070 Ti 炫光 超OC 16GB 评测
前言
英伟达的RTX 50系列以及正式公布了一段时间,市面上也涌现了大量值得一玩的新品,今天我们拿到了来自耕升的GeForce RTX 5070 Ti 炫光 超OC(以下简称为耕升RTX 5070 Ti 炫光 超OC),接下来咱们就一起看看这张“RTX 5070 Ti”有何特别吧。

GeForce RTX 5070 Ti规格一览
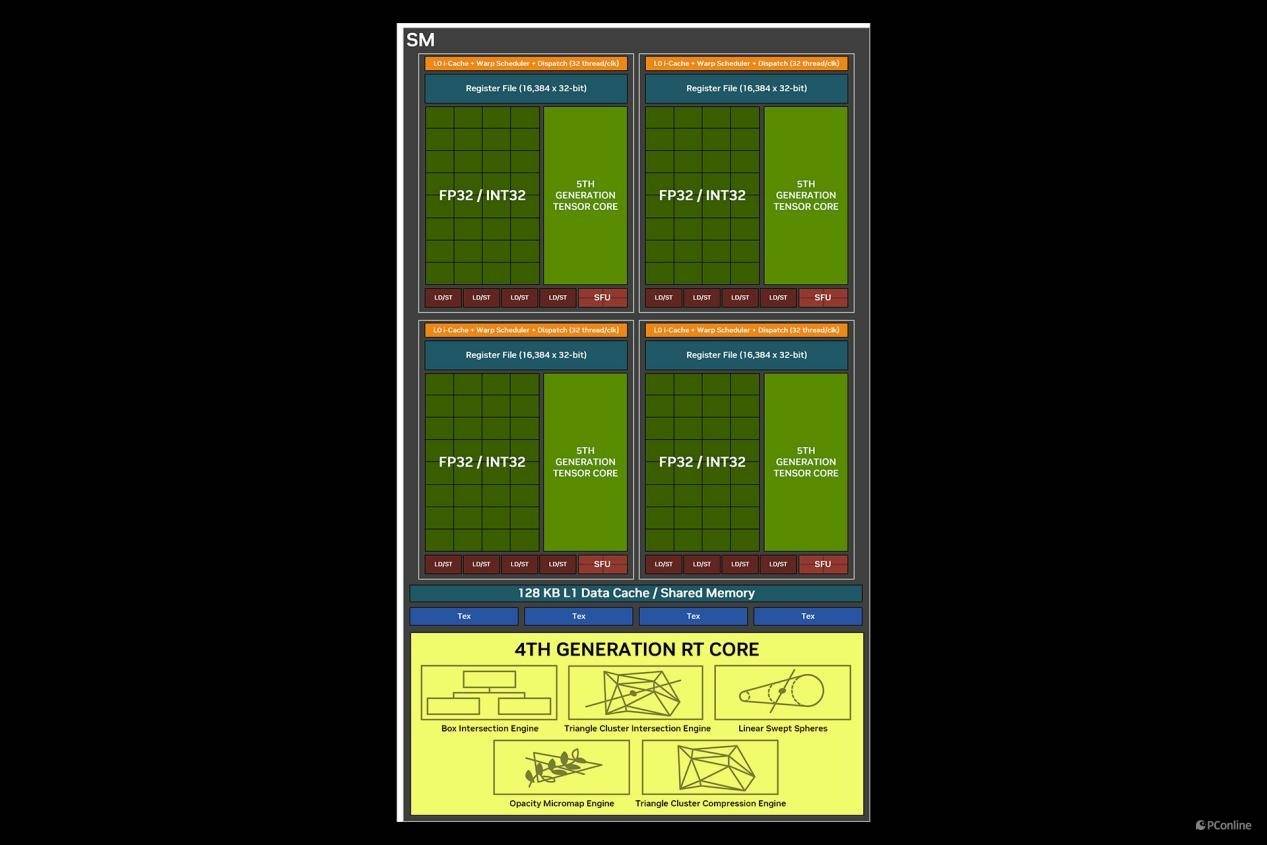
循例先来看看这张的规格,GeForce RTX 5070 Ti 基于Blackwell架构打造,工艺制程是熟悉的台积电 4nm 4N NVIDIA 定制工艺。Blackwell架构的通用算力、光追性能以及AI性能与CUDA数量、第4代RT Core以及第5代Tensor Core的数量有关,而这三种核心又组成了全新一代SM单元。
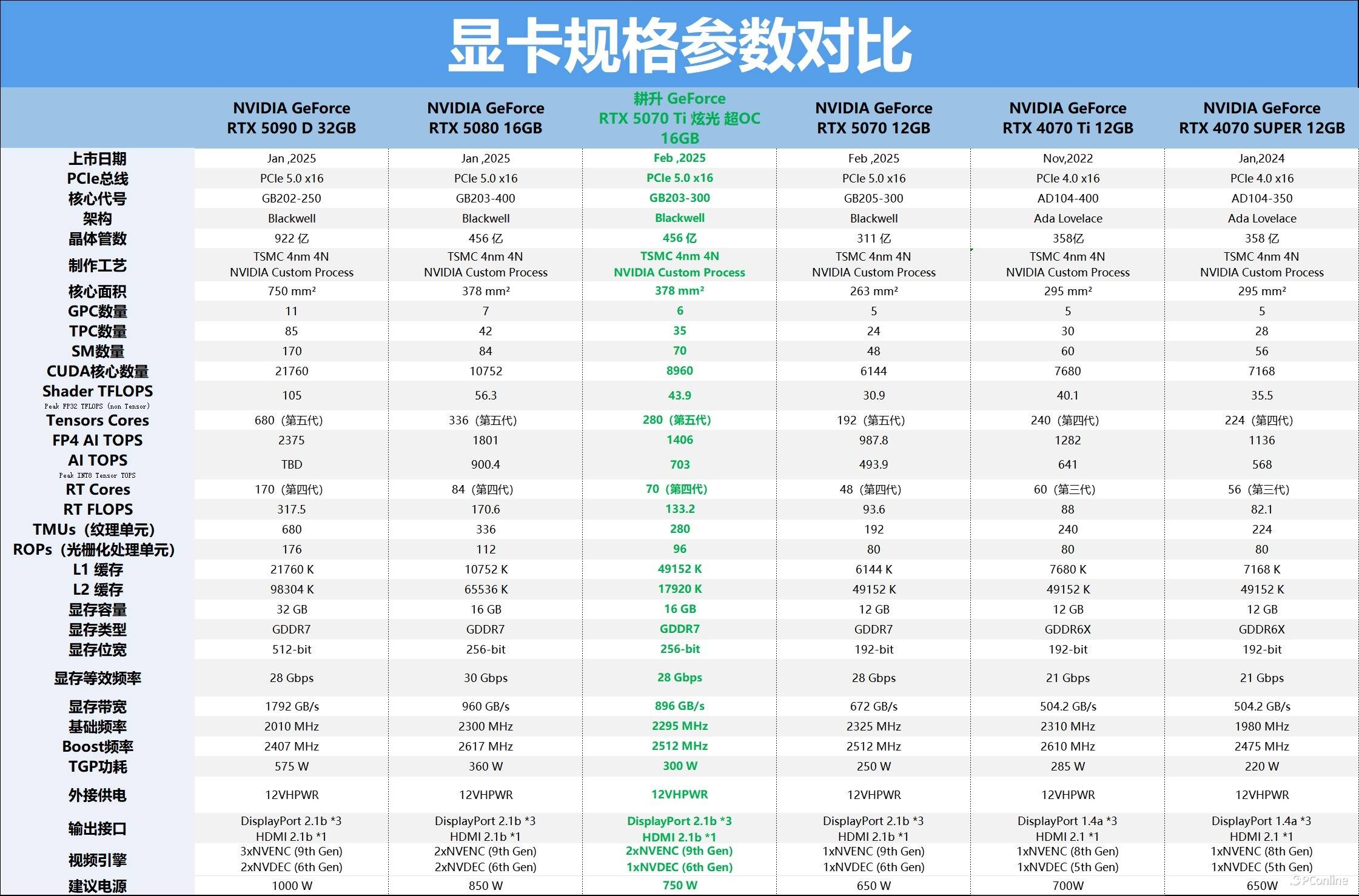
接着再看看规格表,顾名思义,耕升RTX 5070 Ti炫光超OC是一张超频型非公版,其加速频率达到了2512 MHz,这款显卡的另一大亮点是多达16GB的256-bit GDDR7显存,而且这代的CUDA规模要远高于RTX 4070 Ti,显存与规格的双重升级意味着它在理论性能这块的代际提升会比较可观。
除了规格升级外,RTX 50系列还带来了以DLSS 4为首的行业领先技术,这些技术的解释我们放到了最后,有兴趣的小伙伴可以拖动到文末了解,接下来我们先看看游戏性能的表现。
游戏性能测试
纸面数据就点到即止,接下来我们直奔主题,看看耕升RTX 5070 Ti 炫光的游戏表现。开始分享数据前先介绍一下咱们的测试平台配置:我们采用了游戏神U——锐龙7 9800X3D,与之搭配的是微星高端主板MSI MPG X870E CARBON Wi-Fi暗黑,以及芝奇Trident Z5 RGB 幻锋戟 DDR5-8000 C38 24GB*2,这套平台的性能理应能将耕升RTX 5070 Ti 炫光 超OC的游戏性能完全发挥出来。

先看看基础的游戏性能,我们测试了《光明记忆:无限》《古墓丽影:暗影》《战争机器5》等11款游戏,并比较耕升RTX 5070 Ti 炫光(超频模式,下同)与RTX 4070 Ti在2k分辨率下最高/极致画质设置下的平均帧差异。
在不启用DLSS 4的情况下,实测耕升RTX 5070 Ti 炫光相较于RTX 4080 SUPER性能提升了23%至43%。在多数测试游戏中,平均帧率超过了100FPS,《古墓丽影:暗影》的平均帧率甚至达到了305 FPS。
以对硬件要求极高的新一代游戏《黑神话:悟空》为例,在2K分辨率和影视级画质设置下,耕升RTX 5070 Ti 炫光依然能提供85 FPS的平均帧率,轻松畅游西游世界。类似的情况也出现在开启光线追踪的《鸣潮》中,RTX 4070 Ti的平均帧率为77 FPS,足以保证流畅的游戏体验,而耕升RTX 5070 Ti 炫光的平均帧率则达到了107 FPS。后者在面对突发的高负载状况时,能提供更高的帧率,有效避免游戏出现突然卡顿的问题。
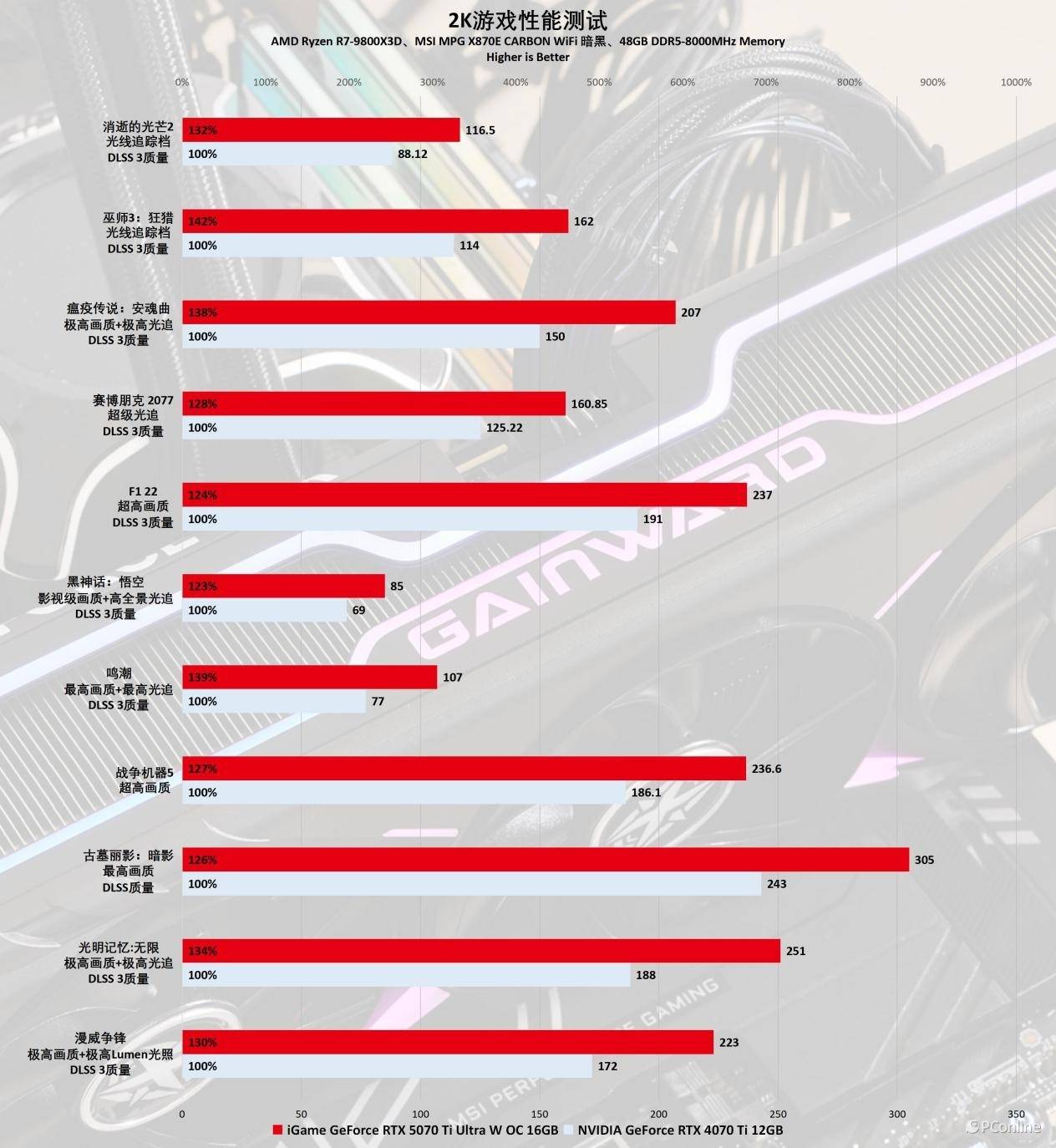
尽管尚未展示RTX 50系列的杀手锏——DLSS 4,但通过比较耕升RTX 5070 Ti 炫光与RTX 4070 Ti的帧率表现,我们可以清晰地看到,DLSS 4(X4)确实为平均帧率带来了显著的提升。
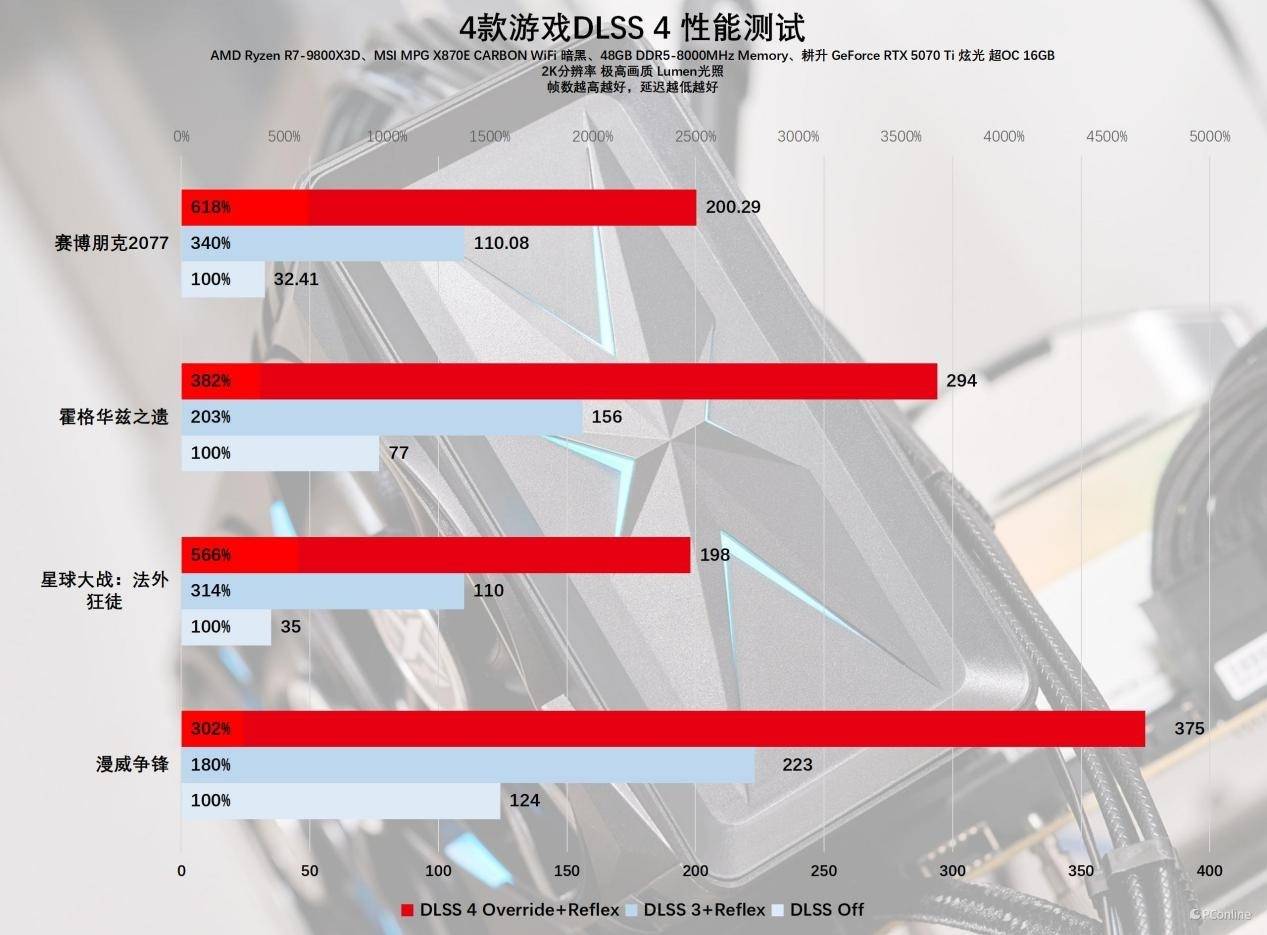
我们选取了4款已经支持DLSS 4的游戏进行对比。根据表格中的数据,显而易见,得益于多帧生成技术的加持,耕升RTX 5070 Ti 炫光 超OC的平均帧率几乎是RTX 4070 Ti的两倍。
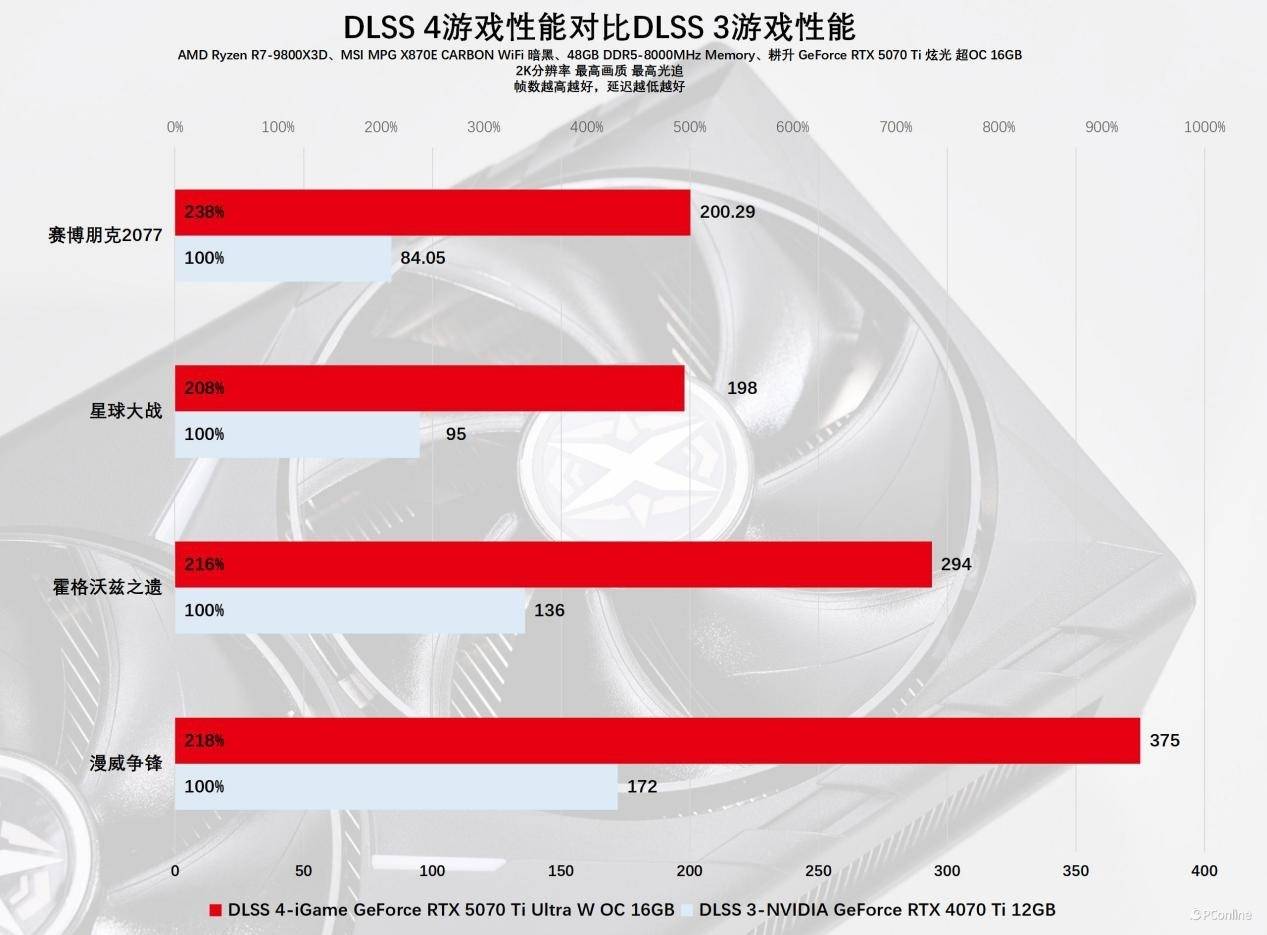
实际上,比较这两张卡的帧率差异已经没有太大意义,我们更应该关注的是耕升RTX 5070 Ti 炫光超OC在开启DLSS 4多帧生成时,与其它DLSS设置相比有何不同。我们对这款显卡在【关闭DLSS】、【DLSS 4帧生成2X】、【DLSS 4帧生成4X】三种设置下的帧率进行了对比测试,测试的游戏包括了4款已支持DLSS 4的游戏。
测试结果令人震惊,当开启【DLSS 4帧生成4X】后,这4款游戏的平均帧率都实现了飞跃性的提升,《赛博朋克2077》的平均帧率甚至达到了原来的6倍。过去我们可能会将这种现象归咎于BUG,但英伟达已经将之变成了现实中的常态。
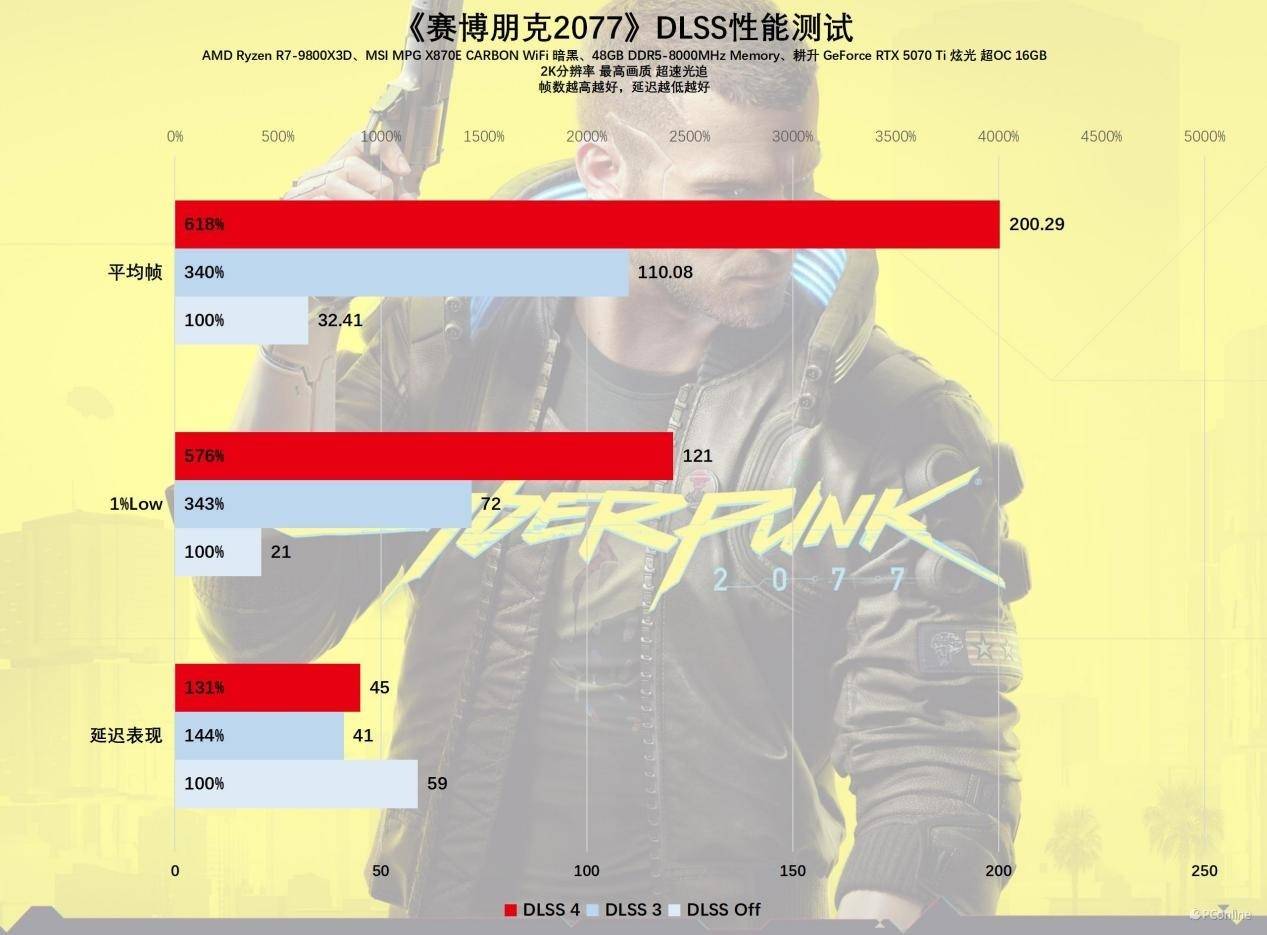
针对目前支持DLSS 4的3A级大作,首先提到了引入路径追踪技术的《赛博朋克2077》。这款游戏的性能要求之高,想必已经为许多了解过的玩家所熟知。先前的RTX 5090 D首测已经展示了50系列显卡能够轻松应对这款游戏。现在,让我们来看看耕升RTX 5070 Ti 炫光超OC显卡的表现如何。在2K分辨率下,未启用DLSS 4之前,平均帧数仅为32.41 FPS,仅达到掌机级别的流畅度。然而,一旦开启DLSS 4,平均帧数激增至200 FPS,而1%的帧数更是飙升至121 FPS,使得这款硬件杀手级别的游戏变得轻松驾驭,同时延迟也得到了显著降低。
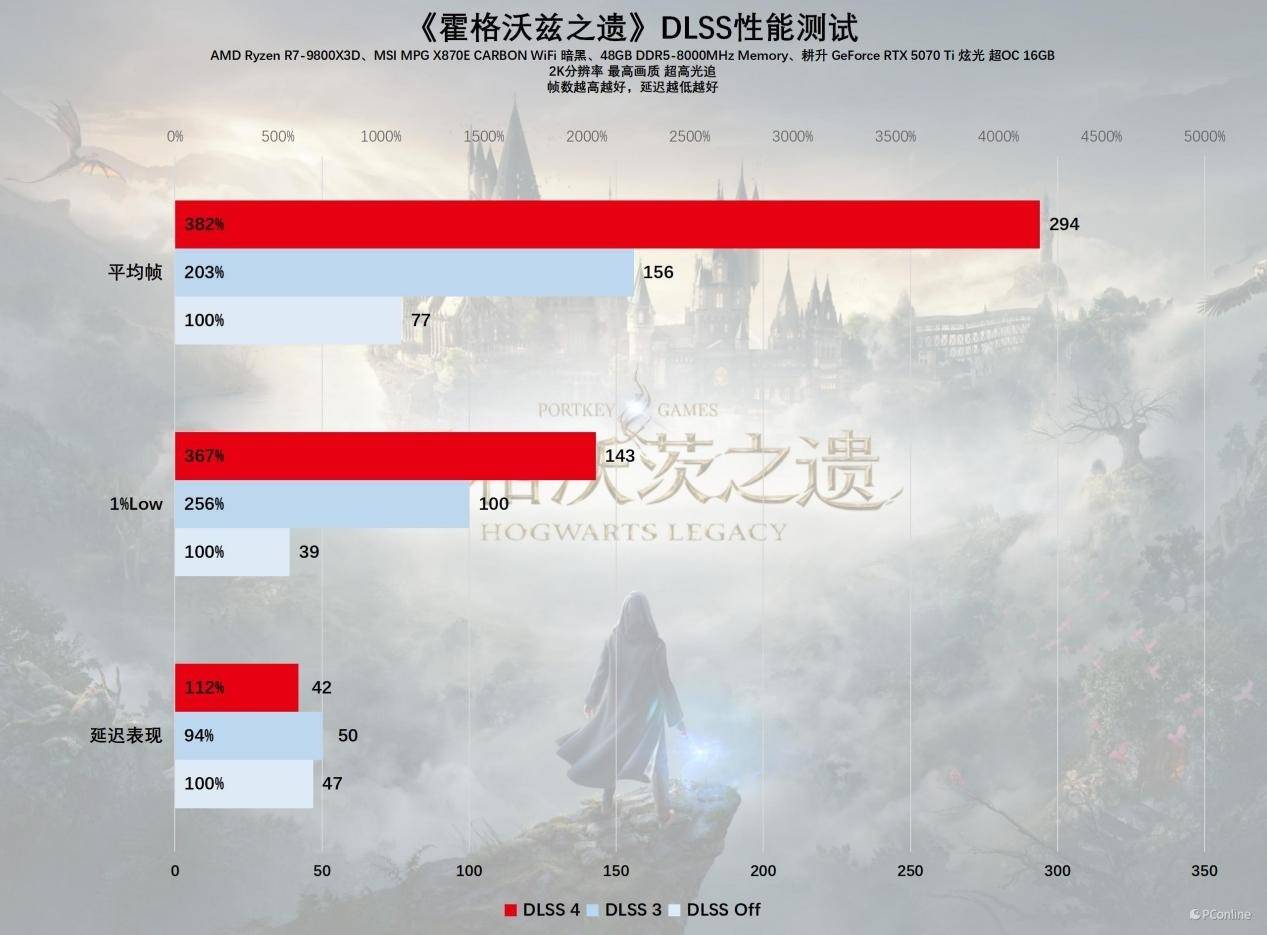
让我们再次审视《霍格沃兹之遗》,这是一款经过良好优化的游戏,即便在不启用DLSS的情况下,也能确保游戏的流畅运行。使用耕升RTX 5070 Ti 炫光超OC显卡,在2K分辨率下关闭DLSS时,游戏的平均帧率可达77 FPS,但需要注意的是,1%的最低帧率仅为39 FPS,这表明在游戏过程中可能会遇到一些卡顿。启用DLSS 4后,游戏的流畅度显著提升,1%的最低帧率飙升至143 FPS,彻底消除了卡顿现象。对于那些追求极致画质的玩家,可以考虑将帧生成技术调整至【2X】模式,以获得更接近原生分辨率的游戏画面。
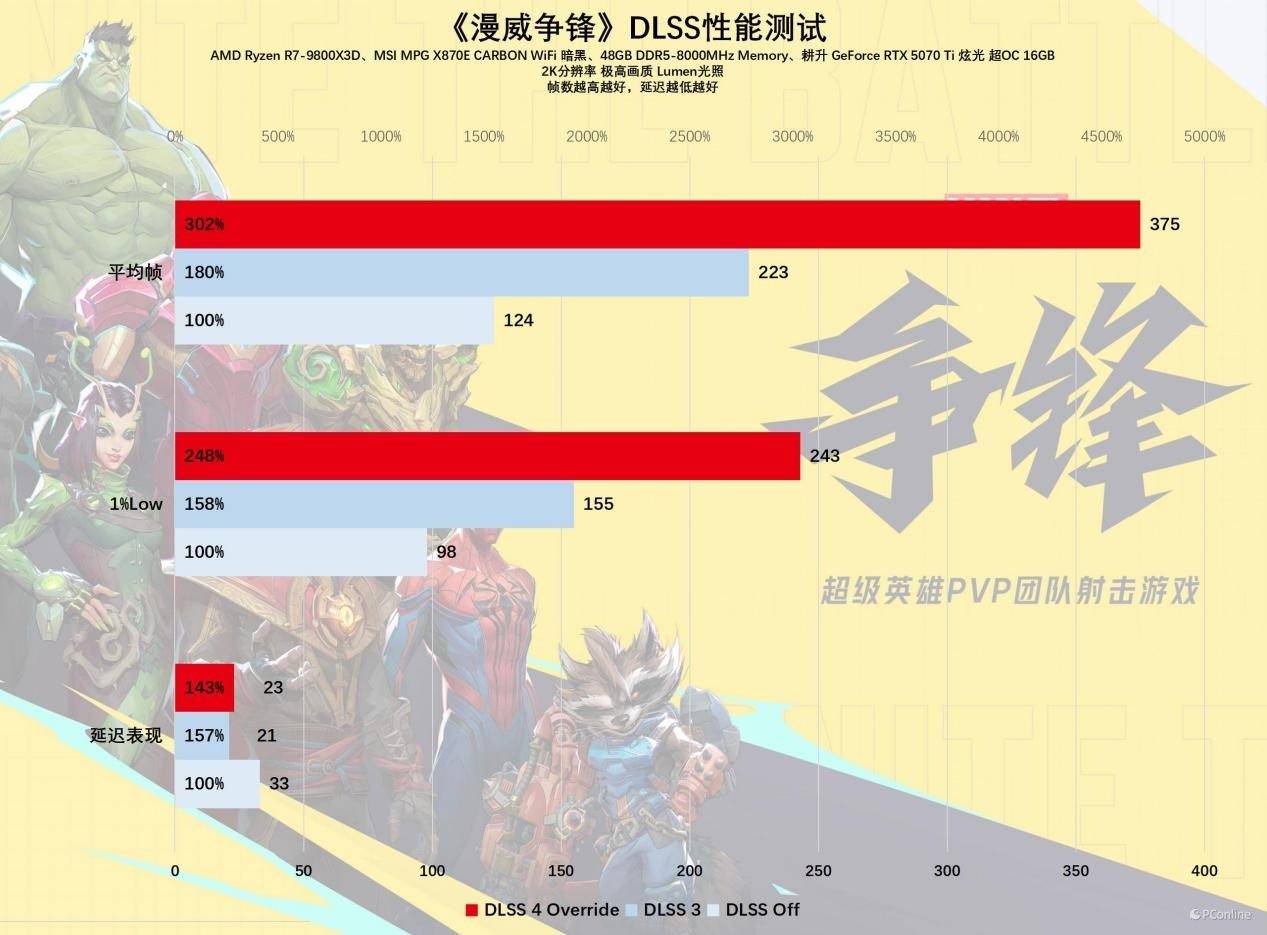
接下来是《星球大战:法外狂徒》,在2K分辨率且未启用DLSS的情况下,26 FPS的1%LOW帧率几乎可以被称作灾难。然而,DLSS 4再次施展其神奇力量,将一款在画质全开时几乎无法游玩的游戏变得流畅,平均帧率足以轻松满足2K@144电竞显示器的需求。
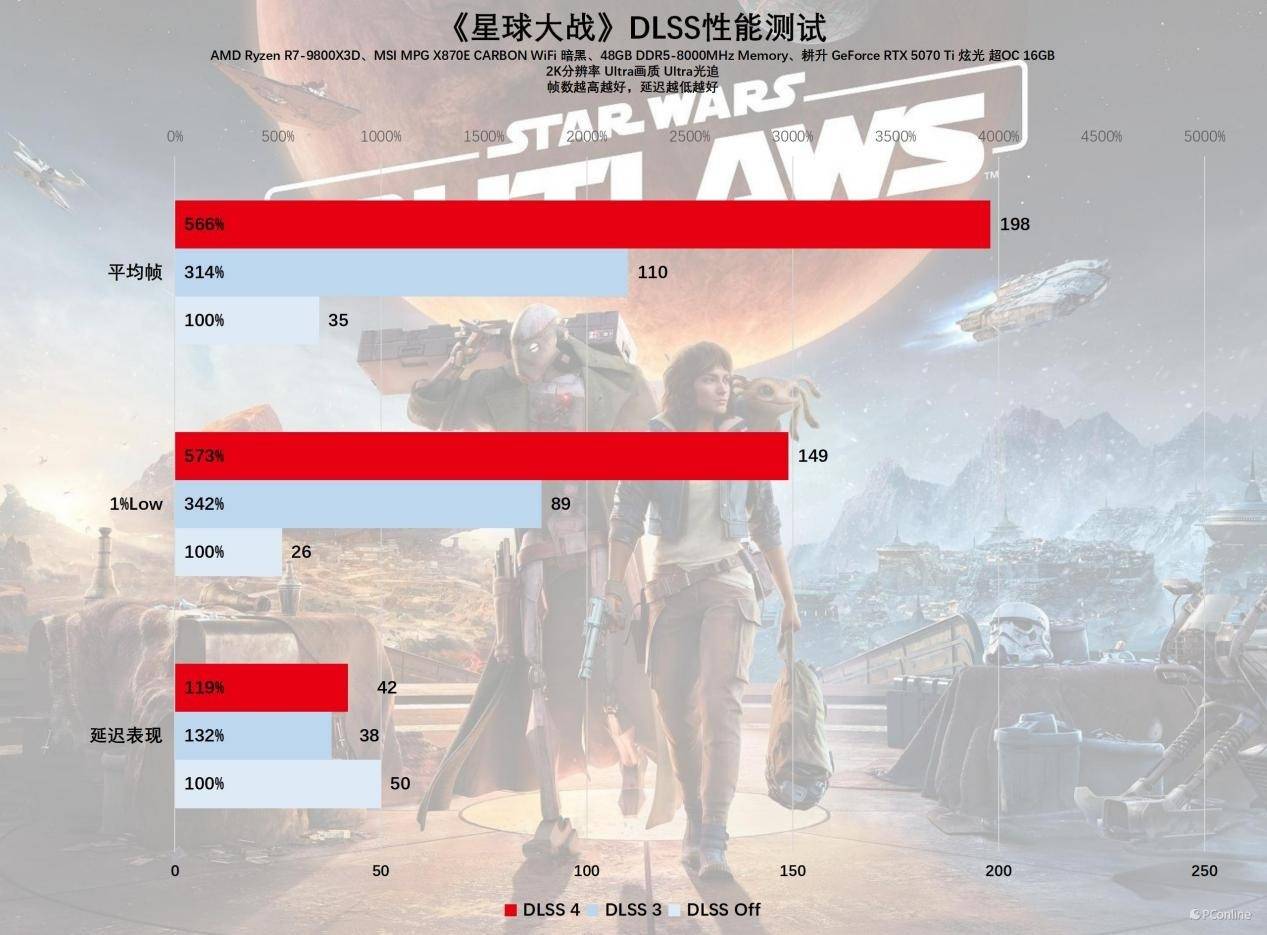
最后是喜闻乐见的《漫威争锋》,竞技类网游对帧率的要求十分高,而这款游戏却有大量画质设定,画质拉满的话配置要求并不低。在2K分辨率未开启DLSS时,耕升RTX 5070 Ti 炫光 超OC的1%LOW为98 FPS,平均帧率仅为124 FPS,对于一款竞技网游来说这帧率表现只算及格。现在有了DLSS 4帮忙,同一张卡的平均帧率突破至375 FPS,1% LOW帧也有243FPS,这流畅度能让高端玩家赢在起跑线。
在观察了四款游戏的性能展示之后,我们可以得出明确的结论:耕升RTX 5070 Ti 炫光 超OC在2K分辨率下,能够轻松满足追求高画质和流畅体验的AAA级游戏需求。即便不计入DLSS 4技术带来的帧率飞跃,硬件性能的提升也得益于CUDA核心数量的增加、第四代光线追踪核心和第五代张量核心的革新,以及16GB GDDR7显存的升级,这些因素共同作用使得游戏性能的代际提升超过了30%。
外观篇:
说完游戏性能再看回耕升RTX 5070 Ti 炫光 超OC本身,先从开箱开始聊起,这张卡的包装显然是经典的N卡包装封面设计,正面是显卡的幻光风格主视觉设计,当然了,3年质保以及支持个人送保这个优势售后信息也标注在了醒目的地方,好让消费者直观地获取到。

包装背面印有硕大的LOGO,上面有显卡的关键特点以及耕升公众号的二维码,消费者在使用过程中遇到麻烦的话,也方便“找到组织”。

打开包装就能见到显卡本体,随显卡还赠送了一根3* 8Pin转12V-2x6转接线,在细节处耕升准备得充足到位。

让我们把所有的包装个配件的先放一边,直面耕升RTX 5070 Ti 炫光 超OC本体。不得不说,这套设计语言虽然简约,但属于耐看的类型。

如今很多高端显卡都追求夸张的、玲珑浮凸的线条设计,其实只要外观做得足够简约、规整和协调,这套设计语言就足够耐看了。

比如耕升RTX 5070 Ti 炫光 超OC的散热器两面,其实没有过多的装饰元素,但是规整的外壳包裹着散热鳍片,这种规则感整体看上去也很舒服。

每一张非公显卡都有独特的散热系统,这张耕升RTX 5070 Ti 炫光 超OC的散热器取自主题,名为“炫之黑曜石”,目前已经进化到第三代,而扇叶则被命名为“炫风之刃”。

显卡的末端处耕升还专门做了一个遮挡设计,这样做一方面能让显卡的整体性更强,但更重要的是可以有效避免使用者直接触碰到散热鳍片,降低“滴血认亲”的概率。

翻到IO挡板,这里也有些小巧思,挡板上的镂空造型并非传统的横条散热格栅,而是心型和C型组成的耕升镂空LOGO。接口方面,该卡提供3个DisplayPort 2.1b和1个HDMI 2.1b接口。

显卡背板的设计也延续了简约的设计风格,背板两边醒目的对称式射线将目光引导至中央的耕升英文名上,靠IO挡板一侧的“射线”是印刷图案,而靠末端的“射线”则是镂空造型,这些镂空位置也有助于显卡散热。

经典的12V-2x6接口位于显卡靠近中央的位置,旁边则是灯光同步接口。

再来看看上机状态,既然它名为炫光,在灯效方面自然不会让人失望,显卡顶部围绕着一圈大面积的RGB灯带,与耕升LOGO灯效相得益彰。

末端处也有灯光覆盖,清晰的棱角线条与浮雕设计相结合,在光影的映照下,创造出令人愉悦的视觉体验。

拆解:
完成上机测试后,自然就是拆解分析的环节。希望了解性能测试结果的朋友可以翻到下一章节。现在,让我们一起深入探讨这款显卡的内部构造。

从全家福拆解图可以清晰看到,耕升RTX 5070 Ti 炫光 超OC主要包括PCB、散热鳍片、合金中框、散热器外框、背板五个部分。散热鳍片上的真空腔均热板+七根镀镍热管组合十分瞩目,其中均热板直接覆盖GPU核心与显存。

七根镀镍热管的规格是两根6mm和五根8mm,这套散热规格理应能在高负荷的工作条件下,将GPU的热量迅速排走。

合金中框可不只是装饰件,它还能增强显卡的整体强度,从而让显卡支撑起厚重的散热模组。

可以看到这张显卡的GPU核心代号为GB203-300-A1,核心一圈围着8颗显存IC。

显存来自三星的GDDR7,丝印为K4VAF325ZC-SC28,显存位宽256bit,显存带宽为896GB/s,一颗显存的容量为2GB,8颗显存IC组成16GB显存。

耕升RTX 5070 Ti 炫光 超OC的组件布局整齐划一,彰显了大厂的风范。该显卡的供电配置为10+4+3相,对于一款300瓦的中高端显卡而言,这样的供电规格无疑是非常豪华的。

负责实际功率调节的IC型号为MP87993,这款芯片在RTX 50系的产品中大量出现。

12V-2x6接口上印有H++标识,这是一个标准的PCIe 5.1 ATX 3.1接口,用来给300W功率的GPU供电当然属于做足了冗余。


PWM控制器被放置在PCB的背面,型号为MP29816。

拆解下来我们发现,耕升RTX 5070 Ti 炫光 超OC的做工及用料均不错,这样在日常使用和装卸中反而能带来更好的可靠性。
基准性能测试——理论性能测试
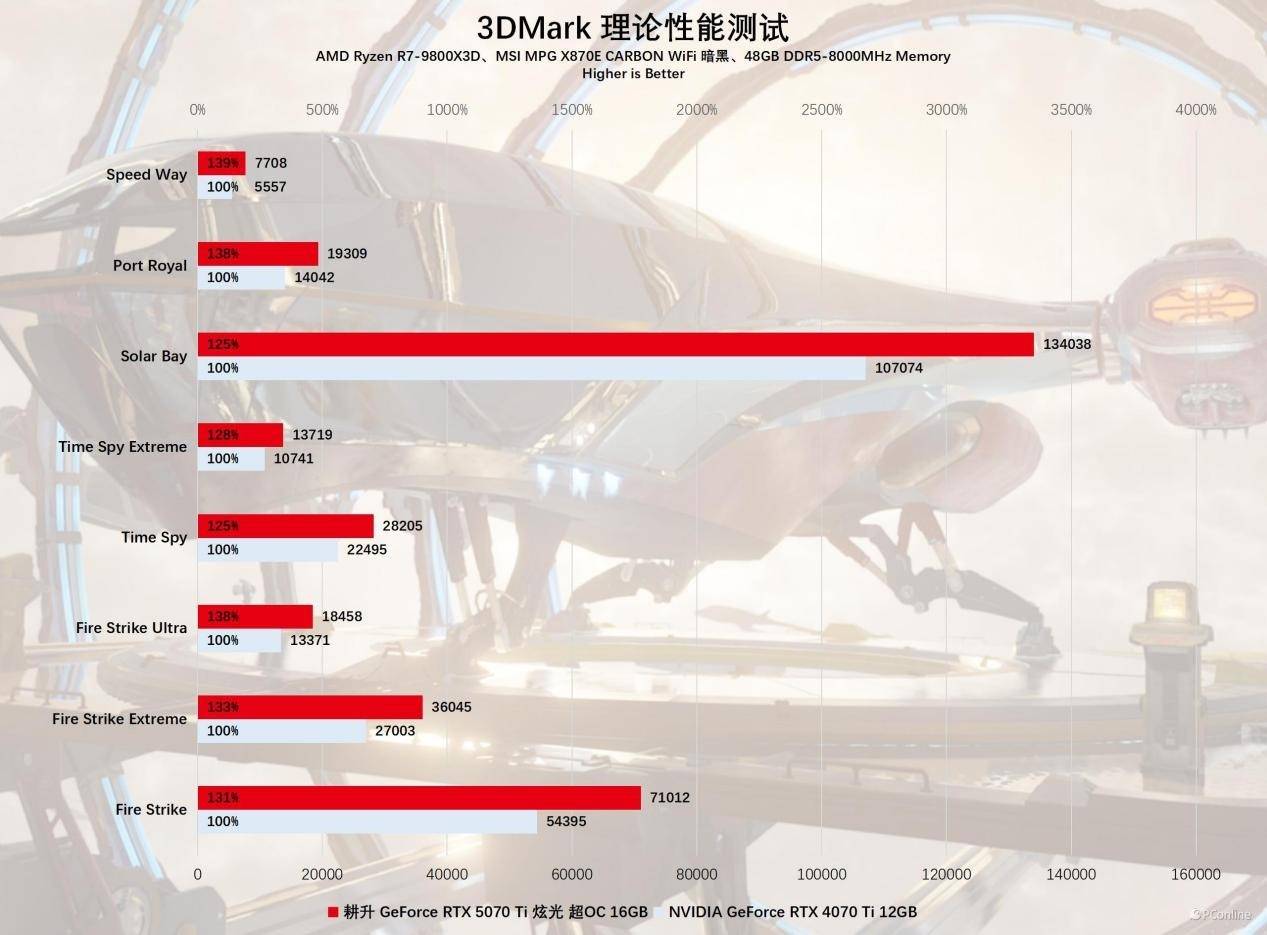
显卡的基本情况分享完毕,接下来当然就是性能实测环节,首先看看理论性能如何,咱们主要参考3DMark基准。在Fire Strike Ultra的基准测试中,耕升RTX 5070 Ti 炫光 超OC的性能大约是RTX 4070 Ti的138%;到了DX12的Time Spy测试中,前者性能是后者的128%;在对显卡压力最高的Speed Way基准中,新卡领先幅度又回到了39%。可见随着图形负载的压力越大,新老两代显卡的性能差异会越来越大。
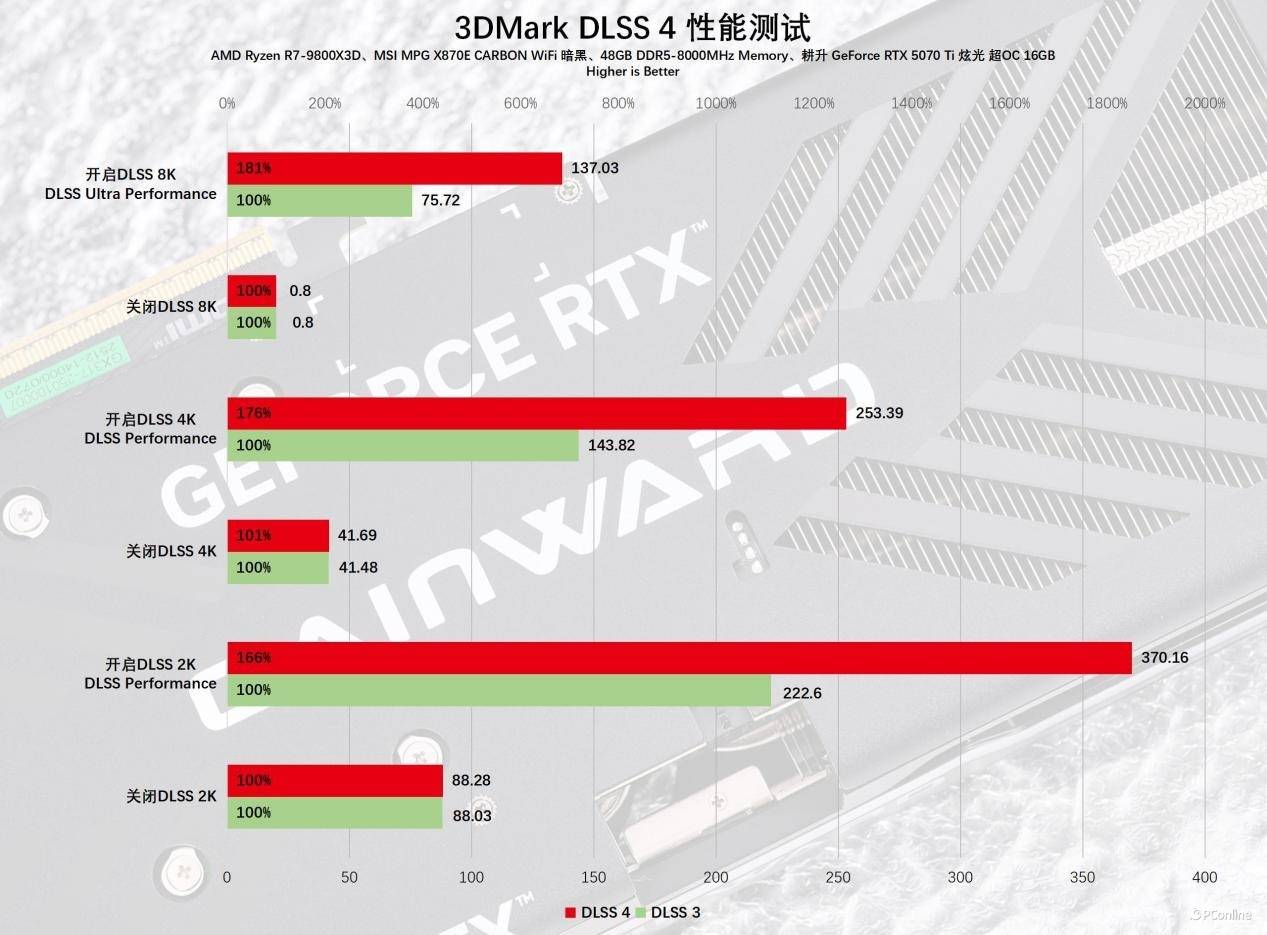
先看看3DMark提供的DLSS 3测试,正如前面提到的结论,新老两代显卡在图形负载越高的时候,性能的差异会越明显,比如8K样例开启DLSS的时候,耕升RTX 5070 Ti 炫光 超OC的性能足足是RTX 4070 Ti的140%,这也真实反映出两者在面临实际游戏场景时的性能差异。
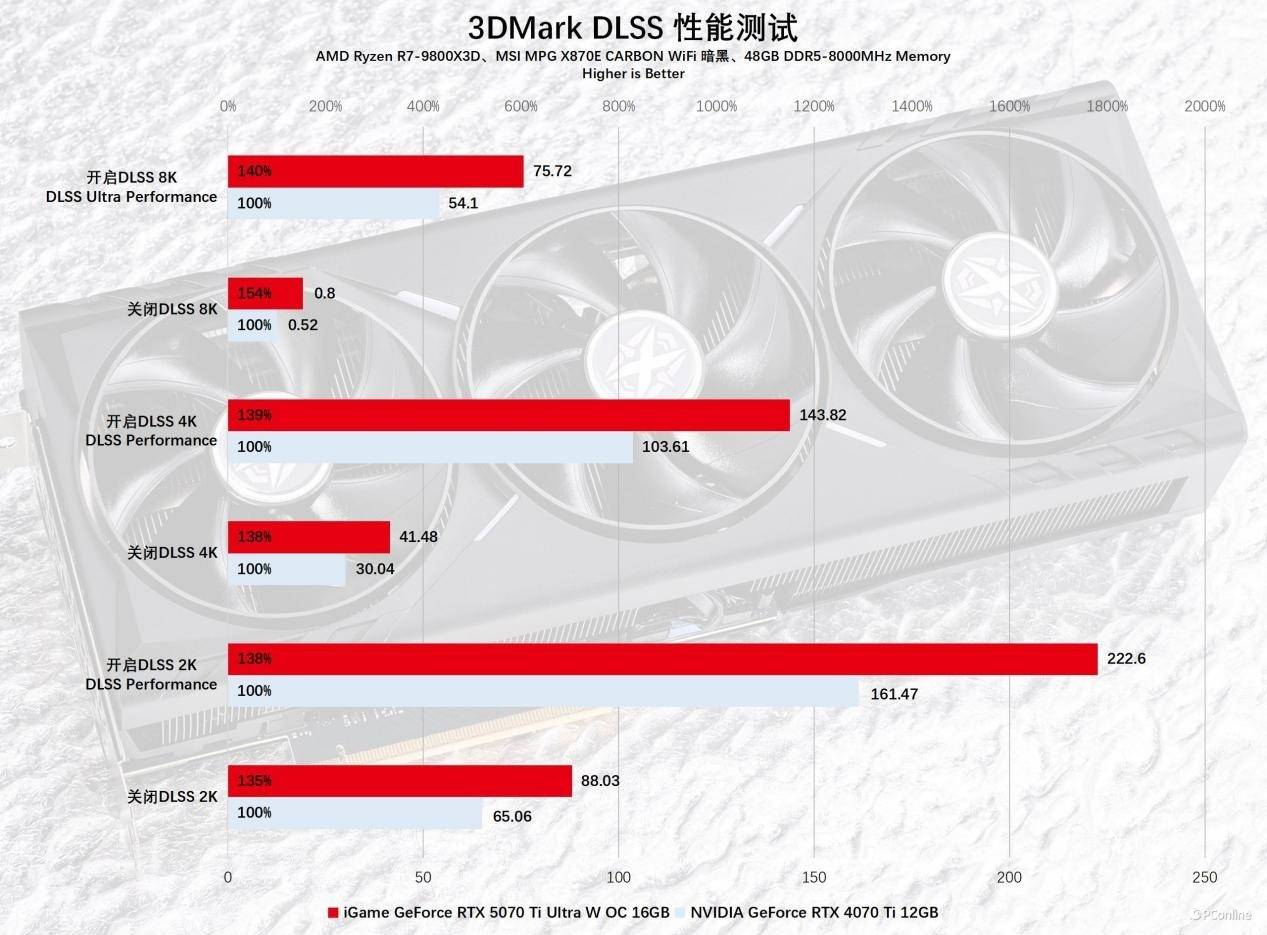
3DMark已经迅速整合了DLSS 4的对比测试项目,从理论性能的角度审视,RTX 50系列显卡的性能展示将极具吸引力。通过实际测试,DLSS 4带来的性能增强效果十分显著。在4K分辨率的测试中,DLSS 4相较于DLSS 3实现了显著的帧率提升。即便在2K分辨率的测试环境下,负载较低时,DLSS 4的帧率也达到了DLSS 3的166%。在8K分辨率的测试中,性能差异尤为突出,启用DLSS 4后,平均帧率达到了137FPS,这种性能的提升堪称耀眼。
基准性能测试——AI性能测试
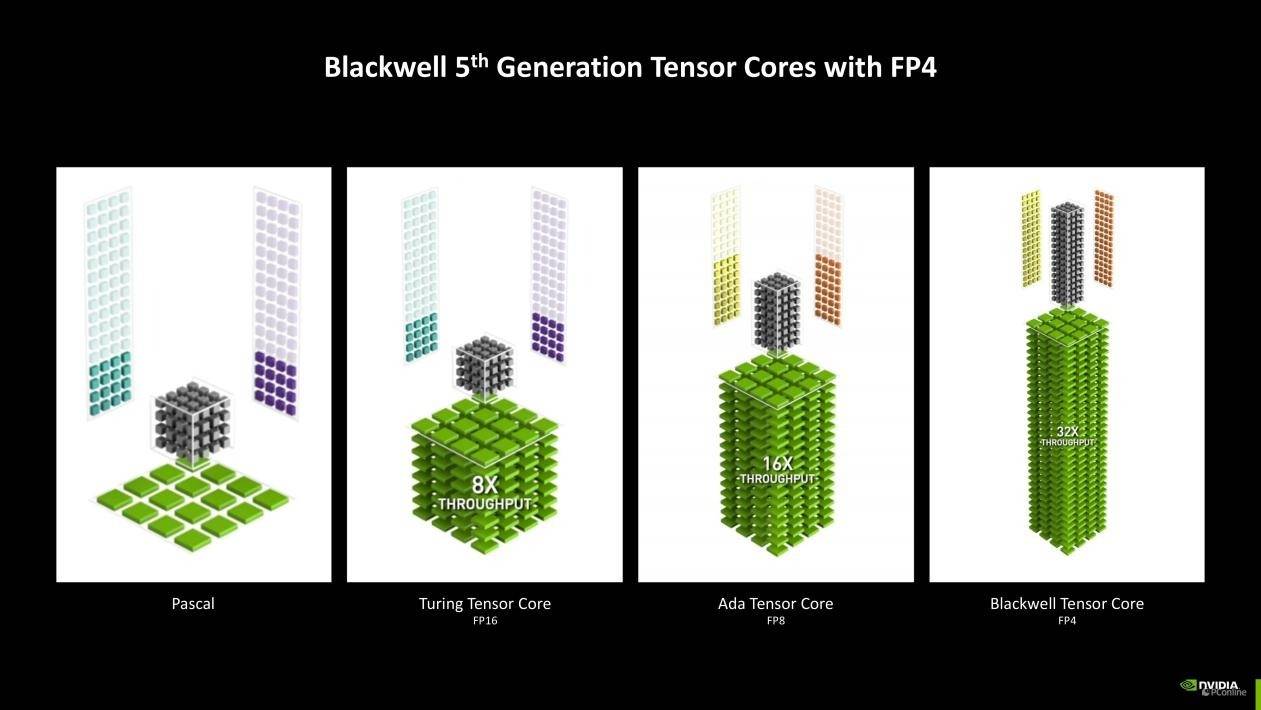
聊完理论性能,我们再来聊时下大热的AI基准。自从ChatGPT横空出世后,PC行业内几乎所有巨头都将AI PC挂在嘴边,但真正要在本地部署AI并用本地硬件轻松跑通这些大模型,英伟达提供的硬件敢说第二,应该没有厂商敢认第一。正如CES 2025上英伟达提到了AI如何塑造RTX 50系列。这代新品的其中一个重大更新就是原生支持FP4精度模型,根据英伟达的官方说法,有了这项新特性,RTX 50系相比RTX 40系的效率更高,显存占用还更低了。
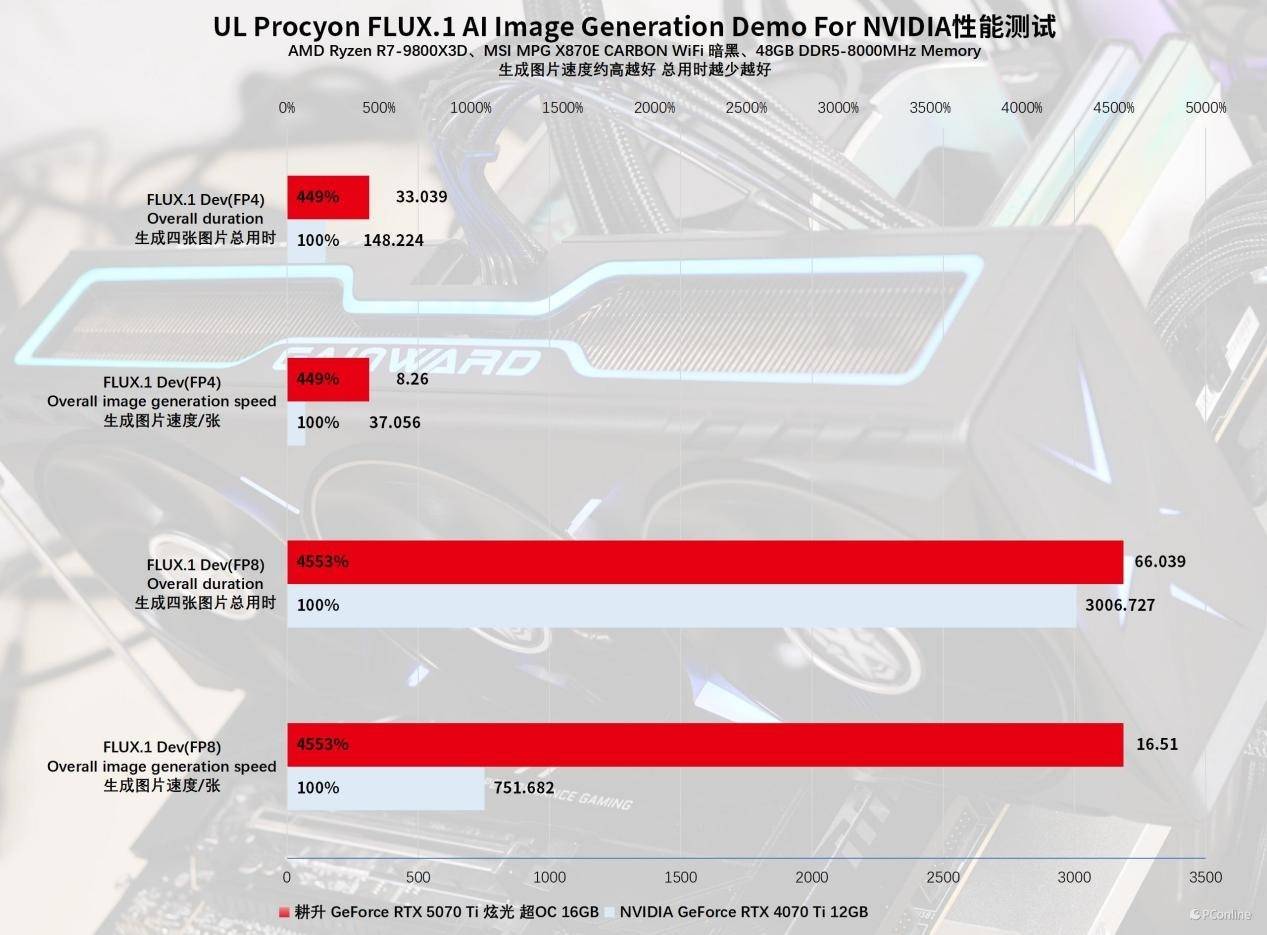
FLUX.1 AI图像生成演示软件针对NVIDIA基准的测试结果,不仅揭示了FP4精度的潜力,还凸显了在AI应用中大显存容量的显著优势。在FP8精度下,两块显卡的性能差异显著,尽管数百倍的性能差异显然不是两种显卡真实算力的直接反映,但根本原因在于它们显存容量的差异。当RTX 4070 Ti的12GB显存溢出时,部分任务不得不转为+GPU“混合双打”,这会显著降低性能表现。然而,在FP4精度下,性能表现得更符合实际情况,RTX 4080 SUPER需要超过半分钟才能生成一张图像,而GAINWARD RTX 5070 Ti 炫光仅需8秒,这一对比充分展示了原生FP4精度的优势。
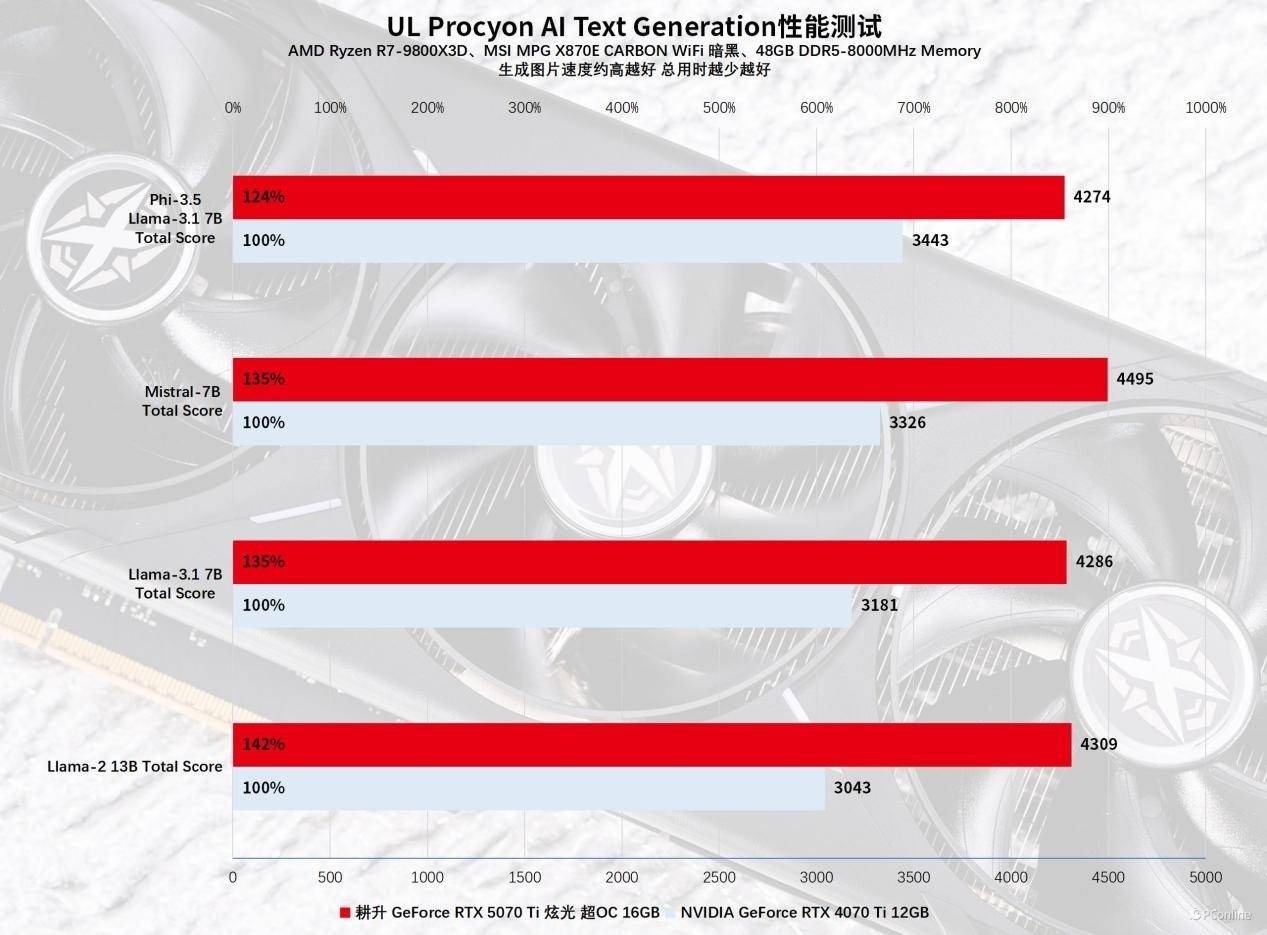
再来看另一个AI基准——AI Text Generation Benchmark,这是一个集合了PHI 3.5、LLAMA 3.1、LLAMA 2等多种大语言模型的基准测试软件。从实测结果来看,耕升RTX 5070 Ti 炫光的表现可圈可点,除了PHI 3.5外,其他基准对比RTX 4080 SUPER均有30%~40%的领先,随着以后FP4精度模型的推广和普及,RTX 50系的优势势必越来越明显。
再来看看MLPerf Client v0.5,这项AI基准更倾向于实际应用场景,比如针对创意写作、长文摘要等场景的测试,实测耕升RTX 5070 Ti 炫光的领先幅度均在40%以上,可谓遥遥领先。

基准性能测试——创造力性能测试
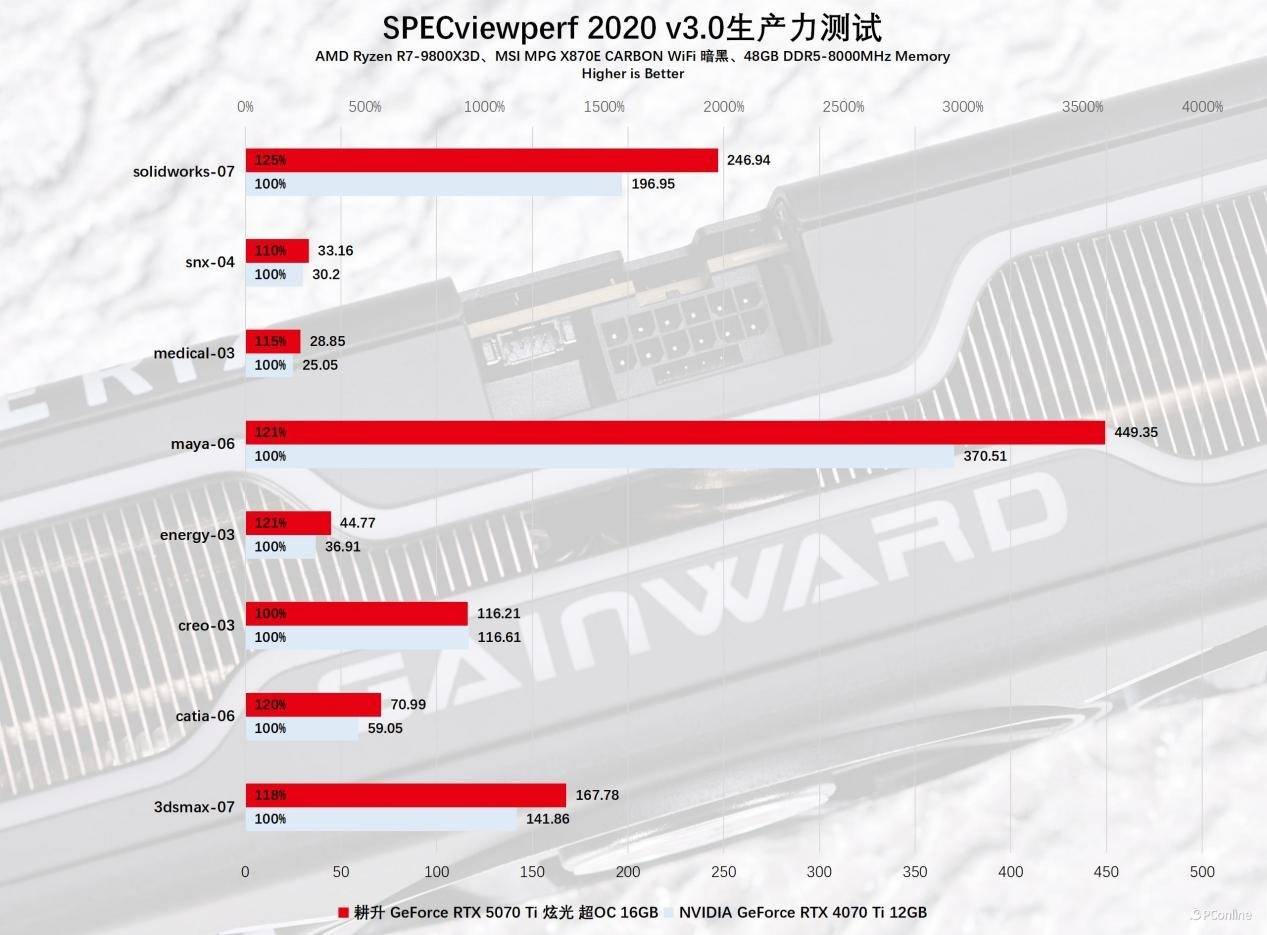
看完以上几个基准,相信大伙对耕升RTX 5070 Ti 炫光 超OC的AI性能已经有一定的了解,对于那些以视频或者3D创作为谋生手段的从业者来说,N卡也是热门的创造力工具。RTX 50系列在创造力方面的提升同样明显,首先不得不提到的是第九代NVENC,即新一代的英伟达编码器,它可以输出H.264/H.265 4:2:2编码的视频,而耕升RTX 5070 Ti 炫光 超OC内置了双NVENC,效率自然更高。

我们使用DaVinci Resolve 19.1.2将一条8K Prores422HQ的无损素材编码分别导出为H.264、H.265、AV1等版本,对比不同版本的导出时间差异。
实测结果着实让人印象深刻,耕升RTX 5070 Ti 炫光 超OC导出这三条不同格式的4K视频比RTX 4070 Ti节省了快一半的时间,尤其是导出逐渐会成为主流的AV1格式视频,用时节省了一大半。而且正如前面所言,它还支持编码4:2:2色度取样的视频,而且实测的导出时间也很优秀。有了这项新特性,耕升RTX 5070 Ti 炫光 超OC不但能为创作者节省大量时间,更能帮助创作者轻松输出更高清无损的视频样例。
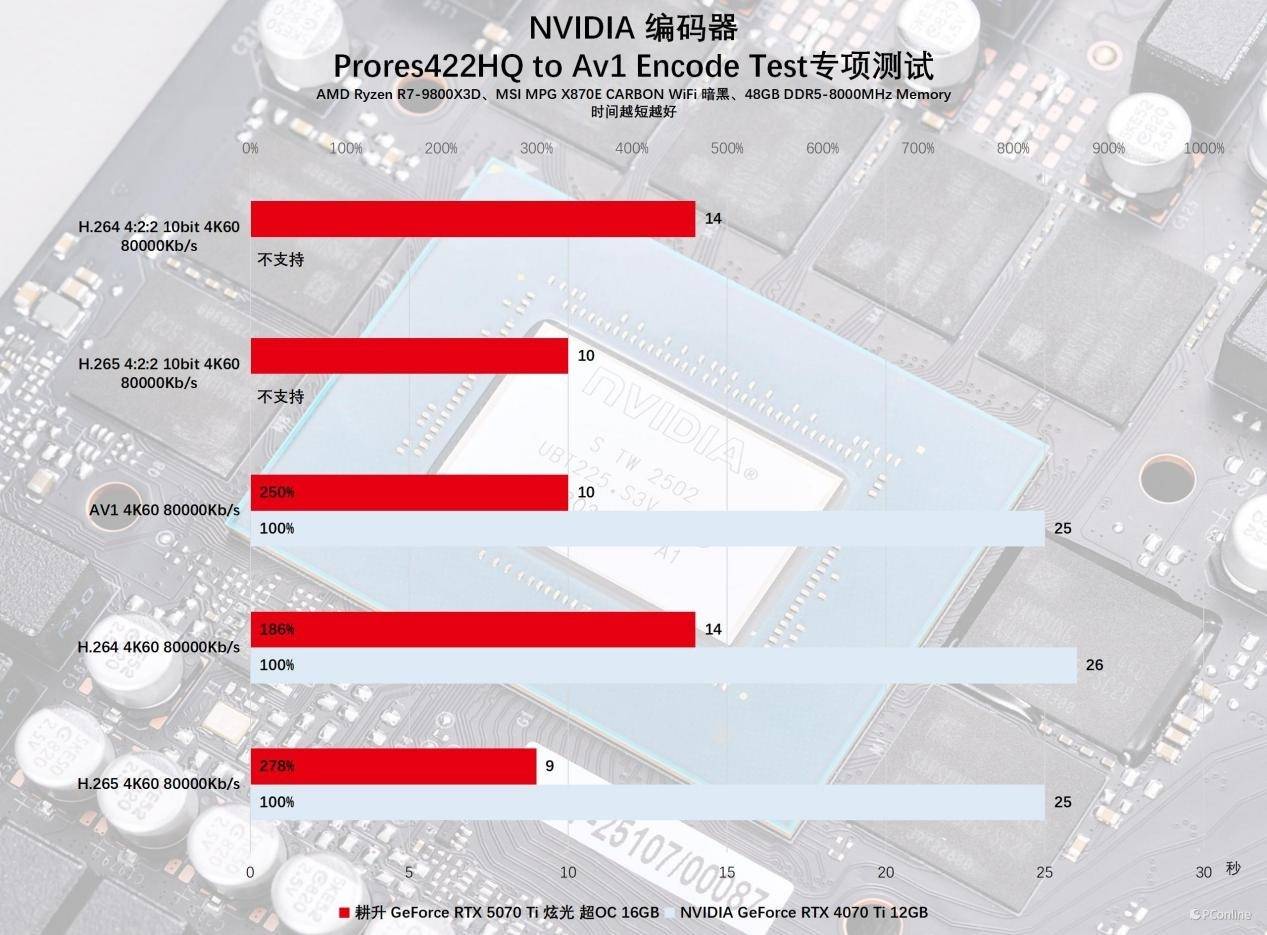
再来看看更贴合真实使用场景的创作力基准——Pugetbench创作力跑分测试,在几款Adobe基准中耕升RTX 5070 Ti 炫光在达芬奇、PR的创作软件的代际性能提升明显,达芬奇软件的测试基准得分代际提升来到了25%以上。
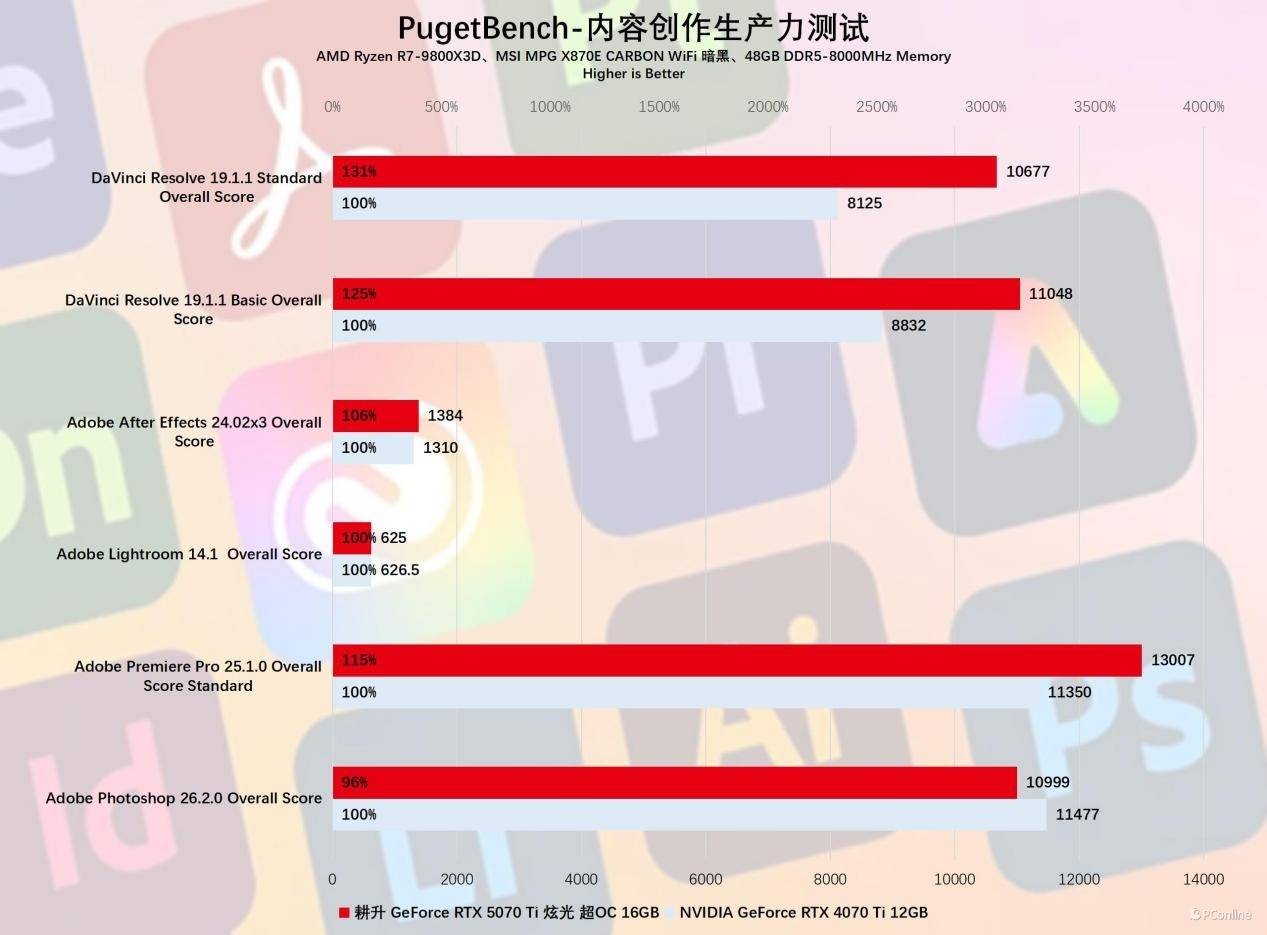
接着是3D渲染软件的性能评估,我们选择了Blender与V-Ray的基准测试。实测耕升RTX 5070 Ti 炫光 超OC在这几个3D渲染基准中平均领先RTX 4070 Ti大约28%。
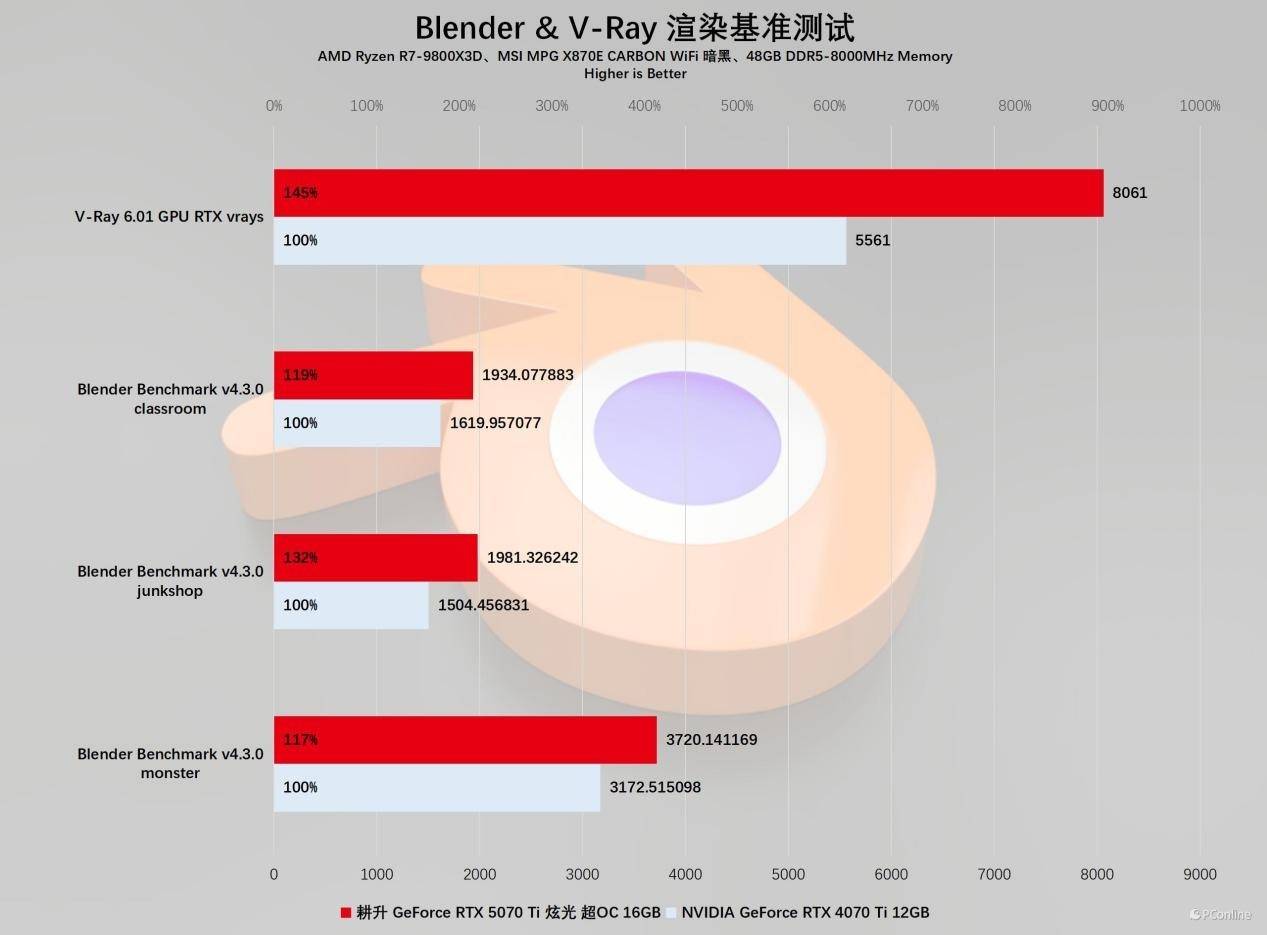
最后是喜闻乐见的工业领域专用软件基准SPEC2020,这项基准测试涵盖了市面上多个工业级生产力软件,能一定程度上反映出显卡的工业生产水平。实测除了creo-03基准外,耕升RTX 5070 Ti 炫光 超OC的代际提升均十分显著,而且提升幅度在10%到25%之间。
总结:
经过实际测试,耕升RTX 5070 Ti 炫光 超OC显卡的性能及其相较于前代产品的提升是显而易见的。特别值得注意的是,该系列显卡已经开始采用16GB显存,这对于那些有意向尝试本地部署人工智能工具的用户来说,提供了更为丰富的显存资源,从而增强了其可操作性。以目前广受欢迎的Deepseek工具为例,16GB显存足以支持本地运行DeepSeek-R1-Distill-Qwen-14B模型,并且能够高效处理一些基础的文书工作。

针对显卡的主要应用领域——游戏,耕升RTX 5070 Ti 炫光 超OC显卡能够轻松应对2K分辨率下各类高端游戏的极致画质需求。更为重要的是,DLSS 4技术的引入使得该显卡在高分辨率游戏运行方面更为高效,实现了画质与流畅性的双重保障,从而确立了其在高端显卡市场中的地位。该显卡不仅在外观设计上独具特色,其散热性能也足以支撑长时间的高性能运行,确保了稳定性。

从实际使用体验来看,耕升RTX 5070 Ti 炫光 超OC显卡在游戏性能、内容创作以及人工智能应用方面均表现出色,能够满足广大用户群体的需求。考虑到其性价比,该显卡被赋予“高端性能守门员”的称号是合理的。尽管其型号为70 Ti,但事实上它已经成为了大多数普通用户的首选。一旦市场价格调整至合理水平,该显卡有望成为市场上的热门选择,进一步巩固英伟达在高端独立显卡市场的领先地位。
GeForce RTX 50系列亮点技术盘点
好了,以上就是我们给出的测试与分析内容,最后给大家介绍一下这一代显卡的架构亮点以及部分技术解析。
Blackwell架构的改进
GeForce RTX 50系显卡采用了此前NVIDIA在AI领域推出的Blackwell架构,以大卫·布莱克威尔命名,其是一名受人尊敬的数学家和统计学家,在博弈论和统计学领域留下了不可磨灭的贡献,NVIDIA用其名字命名这一架构反映了新平台的开创性和先进的计算能力。Blackwell可以说是NVIDIA近年来更新幅度最大的GPU架构了,相比起之前的架构来说,划时代地引入了神经网络着色器,力图为游戏开创先进、高效更为逼真的渲染方式,带给玩家全新的游戏体验。

相比前代Ada架构,Blackwell的升级聚焦于四大方向:分别是AI算力的爆发、光线追踪技术的革新、显存能效的提升以及划时代的神经网络渲染。
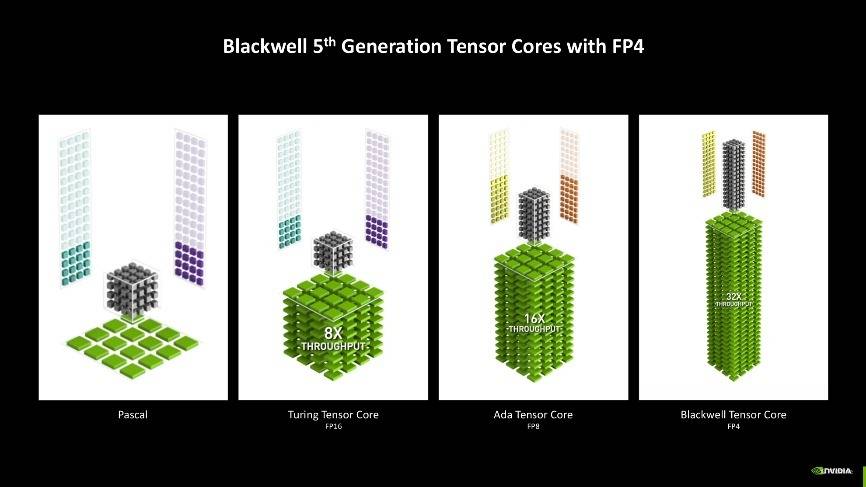
第五代Tensor核心
其中AI算力的爆发就不得不提到Blackwell架构上的第五代Tensor核心,新一代Tensor Core添加了对FP4浮点运算精度的支持。FP4是一种较低的量化方法,类似于文件压缩,可以减小模型推理过程中数据存储和计算量大小,提高计算效率,降低该过程对显存的要求。与大多数模型默认使用的FP16相比,FP4使用的显存不到其一半,并使GeForce RTX 50系列GPU的性能相比上一代提升高达2倍。

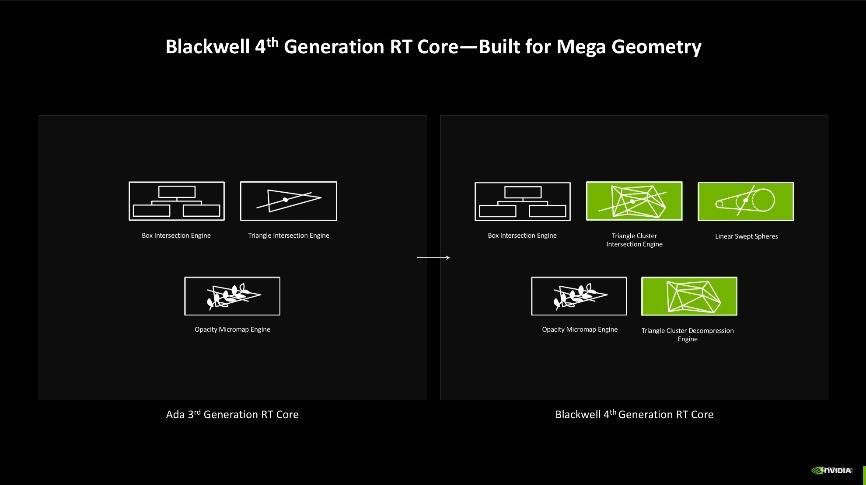
第四代RT核心
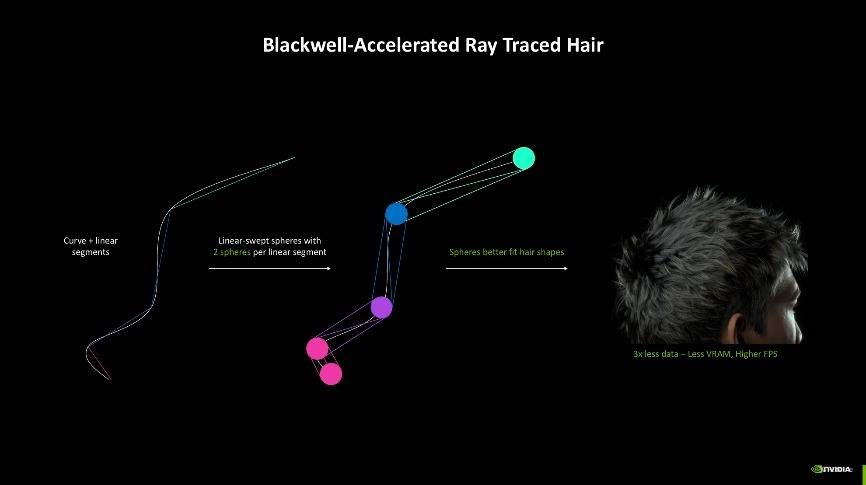
而光线追踪技术的革新则仰赖于第四代RT核心的加持,相较于第三代RT核心来说,Blackwell架构的第四代RT核心主要提升了检测光线、路径与三角形相交的效能,过往在检测时往往只能检测单个三角形,一旦场景复杂,检测能力不足就容易导致渲染出错等问题,而现在检测能够以簇集方式进行,检测效率更高。同时还有三角形簇集解压缩引擎加持,其新增了Linear-swept Spheres(LSS)功能,可以减少渲染毛发所需的几何图形数量,并使用球体代替三角形以获得更准确的毛发形状拟合,能够让显卡发挥更好的性能但只消耗较小的显存占用。
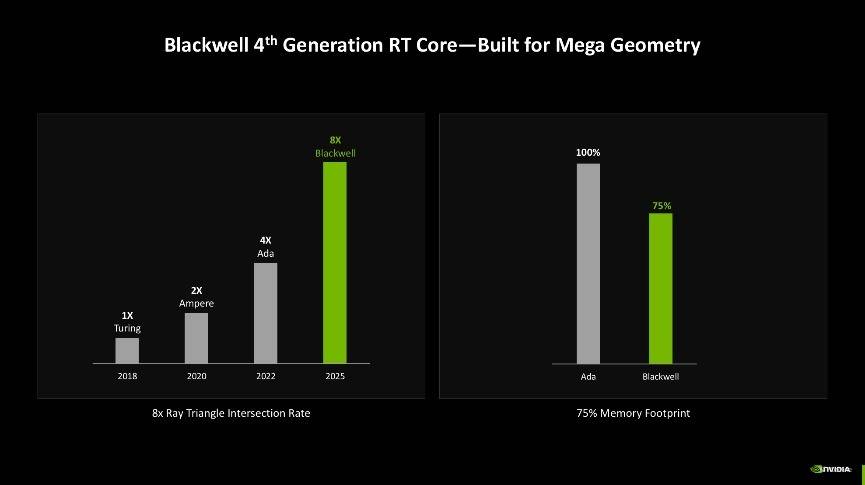
综合来看,Blackwell架构的光线追踪多边形相交效率是上一代Ada架构的2倍,是Turing架构的8倍,同时还可以节省25%的显存使用率。
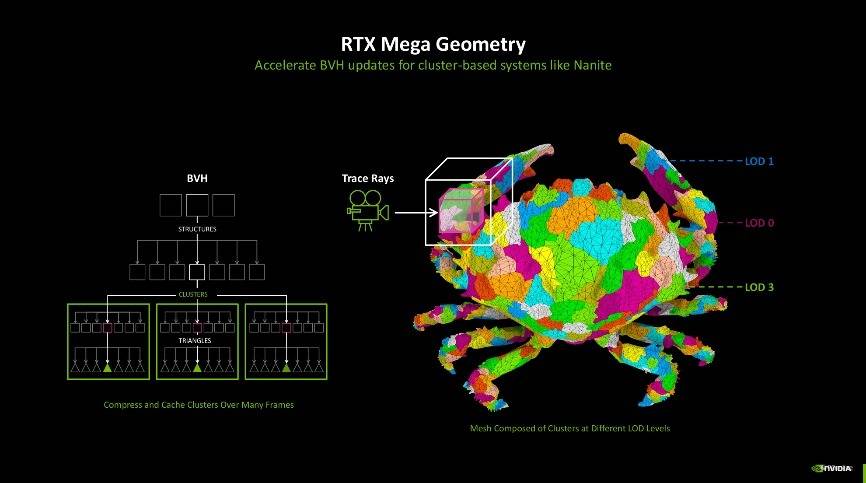
第四代RT核心的改进主要是为实现更好的光追效果。其中有两项新技术能够受益,第一项是RTX Mega Geometry技术。随着光线追踪游戏场景的几何复杂性不断增加,游戏画面中几何图形的计算量也呈现出快速增长的趋势。而RTX Mega Geometry技术能够加速构建边界体积层次结构(BVH),使得在实时渲染中可以处理多达100倍的三角形数量。
该技术的出现,也使得开发者能够在游戏场景中使用更复杂的几何图形,而不会影响游戏帧率。过去需要一个个算BVH,现在RTX Mega Geometry能够智能地在GPU上批量更新三角形簇,减少了CPU的负担,既保证了性能,也兼顾了图像质量。相信随着这些技术的不断发展和应用,未来的游戏将能够呈现出更加逼真和细腻的视觉效果,同时保持高效的性能表现。
另外一个能够受益的技术则是Curve Primitive,方便光追在曲面中的应用,例如一位男士的头发可能需要多达400万个三角形,再加上光线追踪技术,画面所需要的运算负载极大。NVIDIA则通过第四代RT核心中的Linear- Swept Spheres(线性扫描球体)技术有效减少了渲染头发所需的几何体数量,以球形代替多边形,更贴合头发的形状,从而将占用量大幅缩减至三分之一,并进一步提升了实际帧数,让头发的渲染效果更加自然流畅。
GDDR7显存
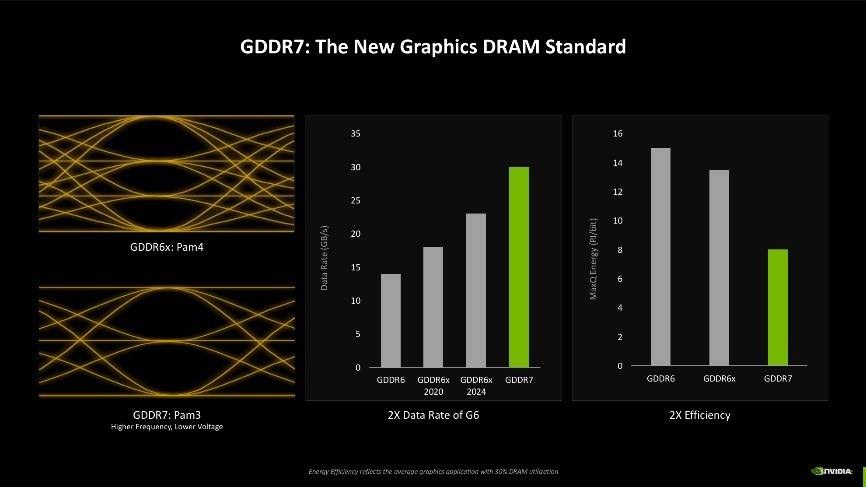
第三点改变则是显存效率的提升,Blackwell架构中还首次加入了对GDDR7显存的支持,此前GDDR6显存的信号编码为NRZ/PAM2,而RTX 40系上的GDDR6X则是PAM4编码。最新的GDDR7显存,信号编码改成了PAM3,NRZ/PAM2每周期提供1位的数据传输,PAM4每周期提供2位的数据传输,而PAM3每两个周期的数据传输为3位。说人话就是,新的编码机制可以使杂讯失真比减小,信号品质更清晰,同时还能带来更高的显存运行频率以及更低的电压,根据NVIDIA的介绍,使用GDDR7显存后,数据传输速率可达GDDR6时的2倍,并且功耗接近GDDR6的一半,经典加量还减价。
神经网络着色器
接着我们再细说一下这一代架构的最大变化,NVIDIA这次将Blackwell架构的SM单元直接称为神经网络着色器。相比较于之前的可编程着色、CUDA统一着色、通用计算着色来说,其最大的变化就是引入了AI,AI将会彻底改变GPU的着色方式。
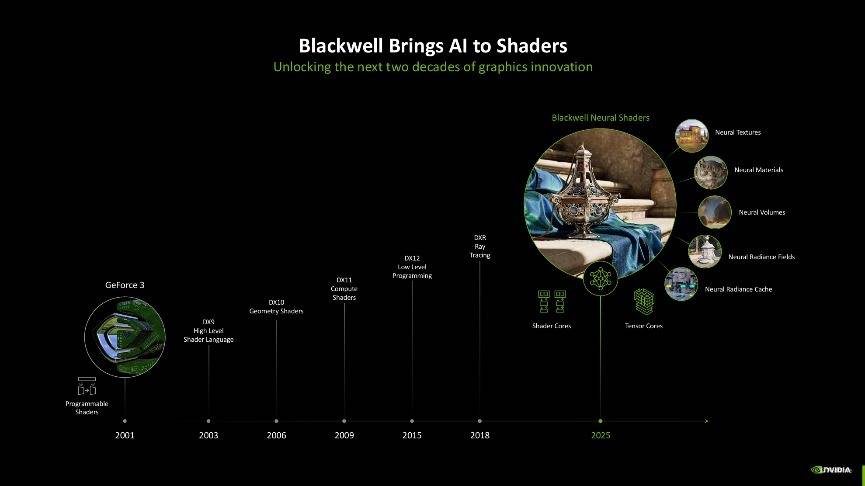
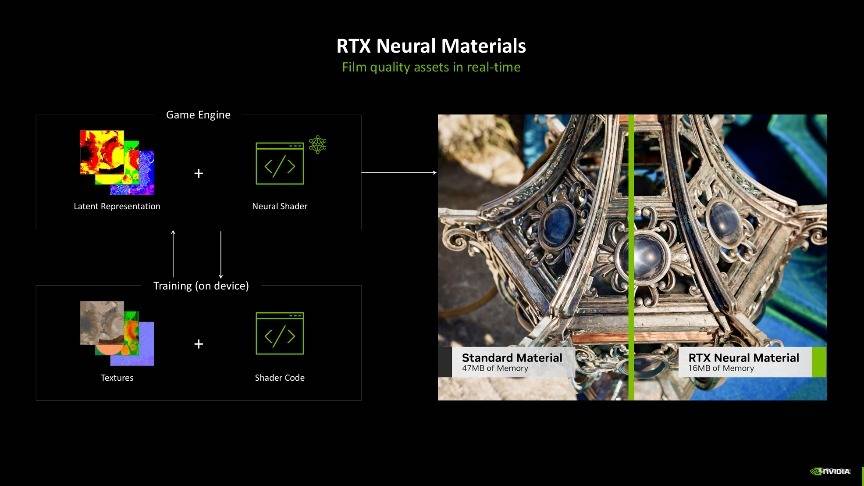
在Blackwell架构中,NVIDIA 进一步拓展了神经网络渲染的范畴,引入了诸多创新元素,包括神经网络纹理压缩(Neural Textures)、神经网络材质(Neural Materials)、神经网络体积(Neural Volumes)、神经网络辐射场(Neural Radiance Fields)以及神经网络辐射缓存(Neural Radiance Cache)等,这些元素共同构成了神经网络渲染中神经网络着色的重要呈现方式。
这里举个例子让大家能够更简单地理解神经网络渲染,过去复杂的物品或大量异材质的贴图往往会占用相当大的内存空间,如果叠加光追的话,计算量将会更大。然而,得益于神经网络渲染技术中的神经网络材质功能,这一问题得到了显著改善。开发者可以先在离线渲染出物品的光照数据,然后再用这些数据训练一个小的AI模型,游戏运行时只要实时调用这个AI模型当场推理就好了,这样就能还原出想要的光照效果了,再配合神经网络纹理压缩技术,就能显著降低实际生成的材质数据量,从而在占用更少显示内存的同时,实现了细节更丰富的材质表现,达到了实时生成如电影般细腻素材的效果。
目前神经网络渲染技术已经得到了微软的大力支持,未来也将会加入DirectX中,玩家能够体验到更真实的游戏世界。
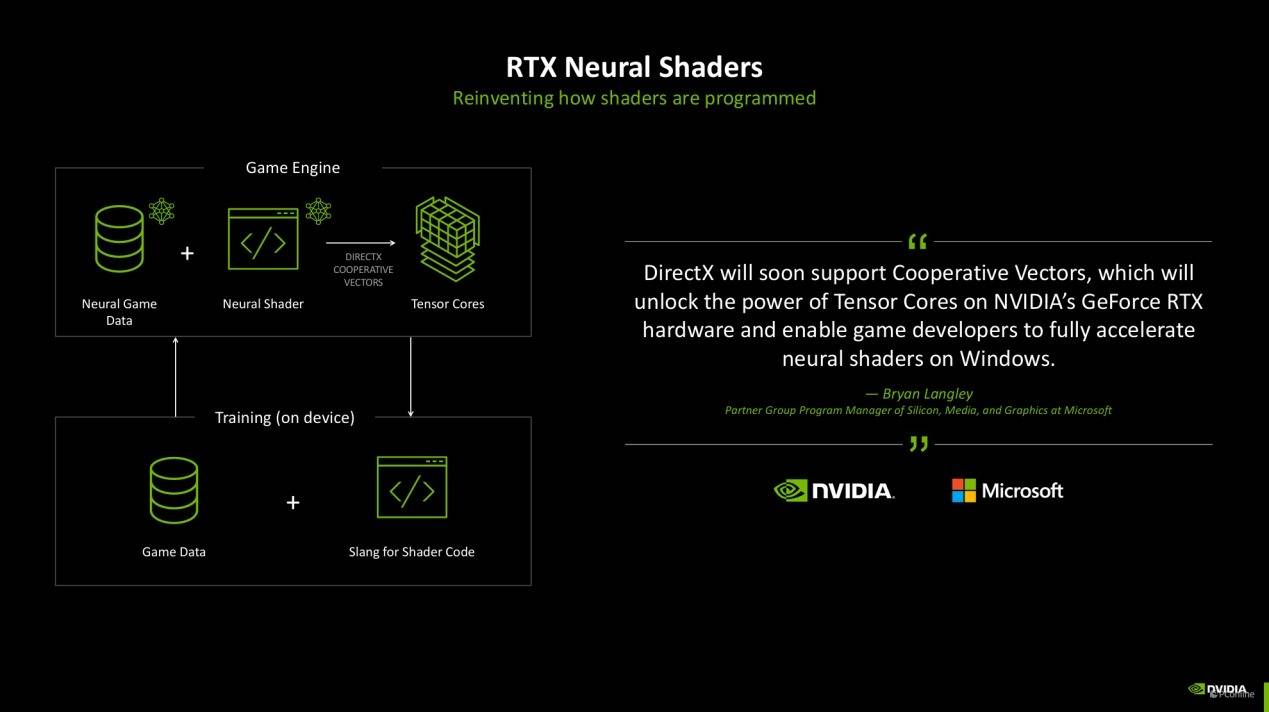
而在硬件层面,由于神经网络渲染的加入,Blackwell架构的SM单元相较于RTX 40系的Ada架构还是有不小变化的,Ada架构内的SM内,SM单元会拆分成一半的CUDA专门用于处理FP 32(单精度浮点数),另一半则依需求动态调整去处理FP32和INT32(32位整数)。而在Blackwell架构上,SM单元则改成了CUDA核心可以完全依需求动态处理FP32和INT32的形式。
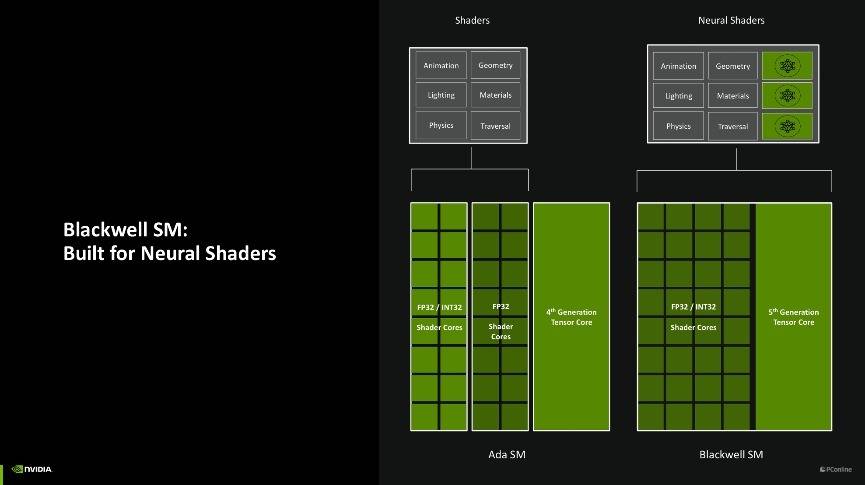
另外一个改进是,过往的着色工作往往只有SM单元的Shader在处理,而Blackwell架构上引入了神经网络渲染以后,使得Blackwell架构上的第五代Tensor核心也能共同分担着色工作,大大提高了着色效率。
这样改进的好处是,Blackwell架构能够进一步针对神经网络渲染工作进行排序,即把传统的着色工作分配给Shader,而需要动用神经网络渲染的工作负载则可以给到Tensor核心上,两种核心同时运用,效率最高可以提升2倍之多。并且得益于Tensor核心也加入了可编程渲染管线,现在开发者或API也能更好地调用Tensor核心,未来游戏内我们能见到的AI技术势必越来越多。
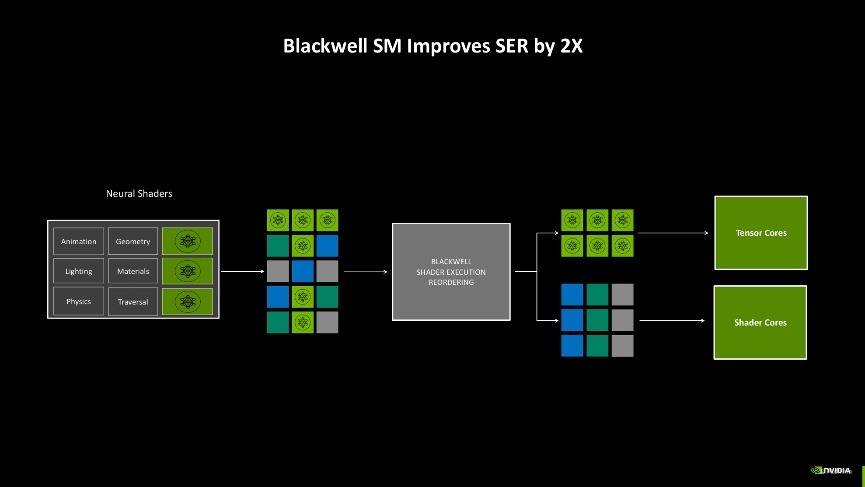
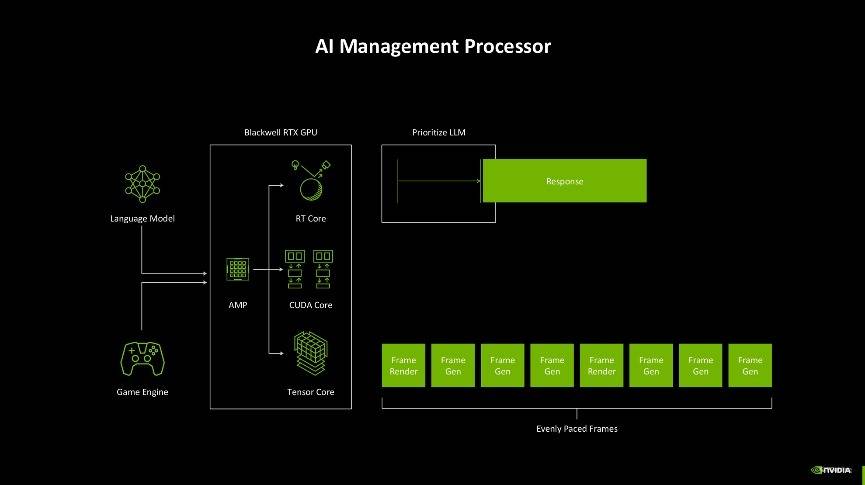
先进的AI管理处理器
此外,AI的应用也越来越多,不仅游戏中应用AI技术,现在连可编程渲染的过程里也引入了AI,因此如何去分配显卡内部多样化工作就成了一个问题。如过往显卡在开启DLSS玩游戏时,其中应用到的语言模型和游戏引擎需要同时与GPU的不同核心交互,生成游戏帧,但是往往很难做到每一帧都有一致的生成时间,抑或是游戏AI对话的响应不够及时,这些情况都会造成游戏体验不友好。
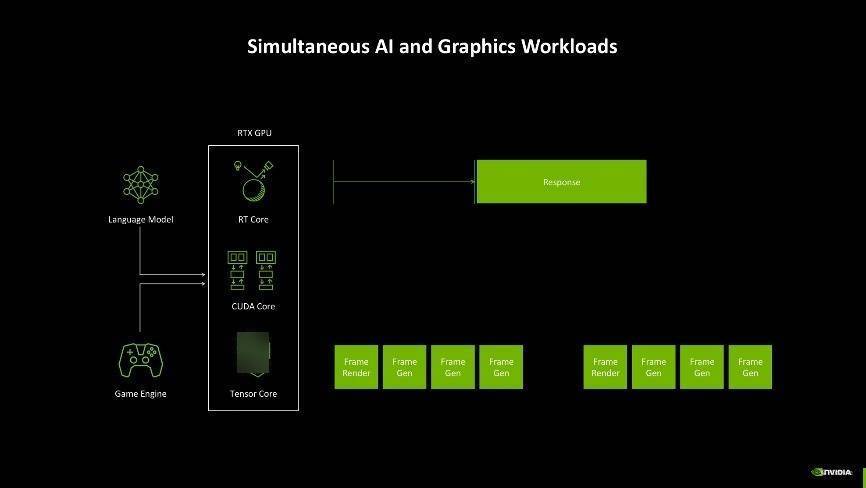
而Blackwell架构为了解决这一问题,引入了AI管理处理器(AMP)。它能够实时调度资源,确保在神经网络渲染、帧生成和 AI 驱动的游戏交互中实现智能化的任务分配。这种设计不仅带来了更高效的性能输出,还让显卡在游戏渲染和 AI 运算之间实现了绝佳的平衡,确保帧的间隔均匀,对话类型的AI能够及时响应,玩家的游戏体验一致性能够比较好地保障。
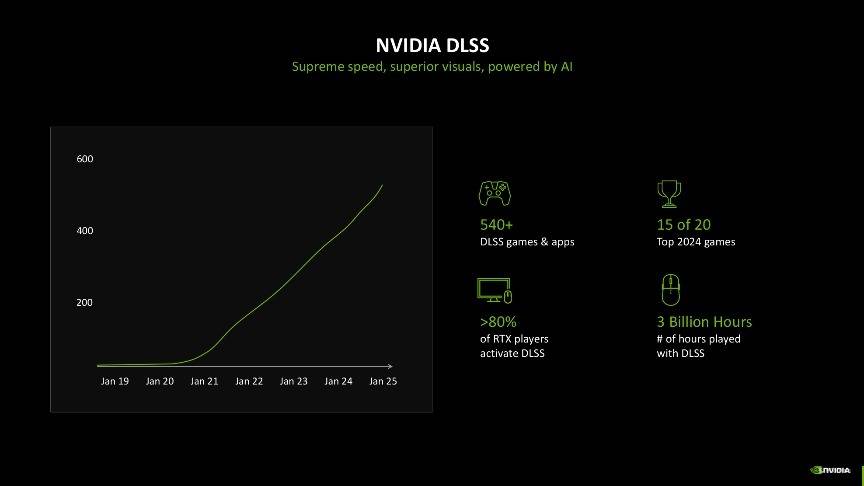
技术解析:DLSS 4
介绍完NVIDIA引以为傲的RTX神经网络渲染,再让我们看看应用RTX神经网络渲染的最好例子——DLSS。它不仅能提高帧率,还可同时提供清晰锐利的高质量图像,效果与原生分辨率渲染媲美。目前支持DLSS的游戏已经多达540款,而玩家使用DLSS的时间更是长达3亿个小时,可以说DLSS给玩家带来了划时代的游戏体验。
目前DLSS已经迭代至DLSS 4,DLSS 4进一步整合了多帧生成 (Multi Frame Generation)、光线重建 (Ray Reconstruction)和超级分辨率 (Super Resolution)等多种先进技术,通过 AI 模型对帧间信息进行深度分析与融合,最终呈现出更具沉浸感与真实感的画面。
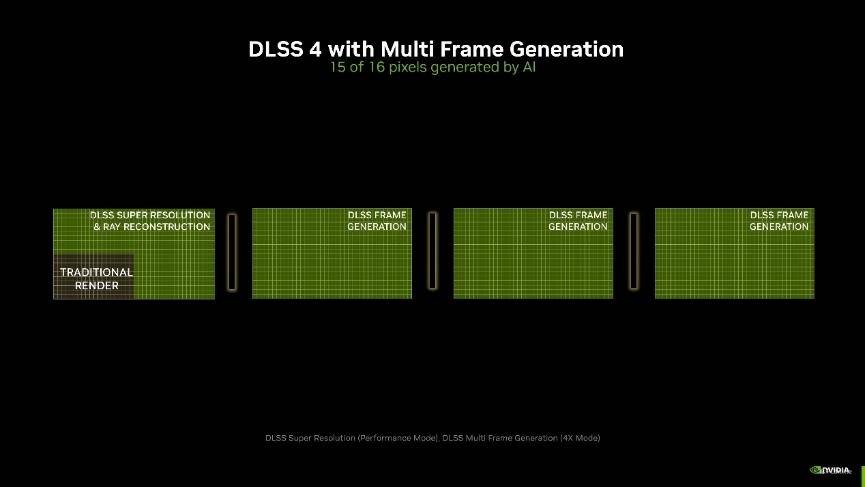
什么是DLSS 多帧生成?
在 DLSS 3 帧生成技术中,AI 模型使用运动向量和深度等游戏数据以及来自 GeForce RTX 40 系列光流加速器的光流场来生成一个额外的帧。由于每生成一个新的帧都需要光流加速器和 AI 模型参与,因此生成多帧的开销相当高昂,而过高的性能开销会带来瓶颈,导致帧率提升受限。
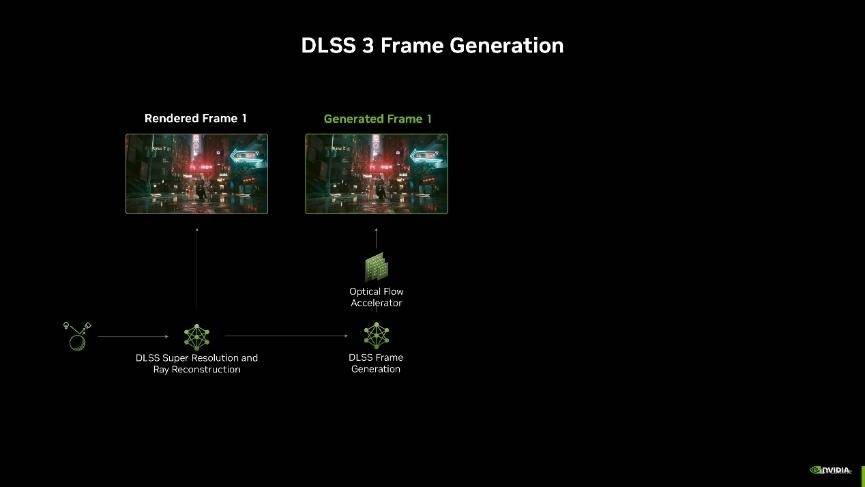
而这次DLSS 4全新升级,引入了多帧生成技术,它可以利用 AI 为每个渲染帧额外生成多达3帧!相比传统渲染的方式,能够最多实现8倍的性能提升。并且每次渲染额外帧只需要AI模型执行一次,就能输出三帧画面,因此无论是对性能、显存的开销还是延迟都比之前要好了许多。
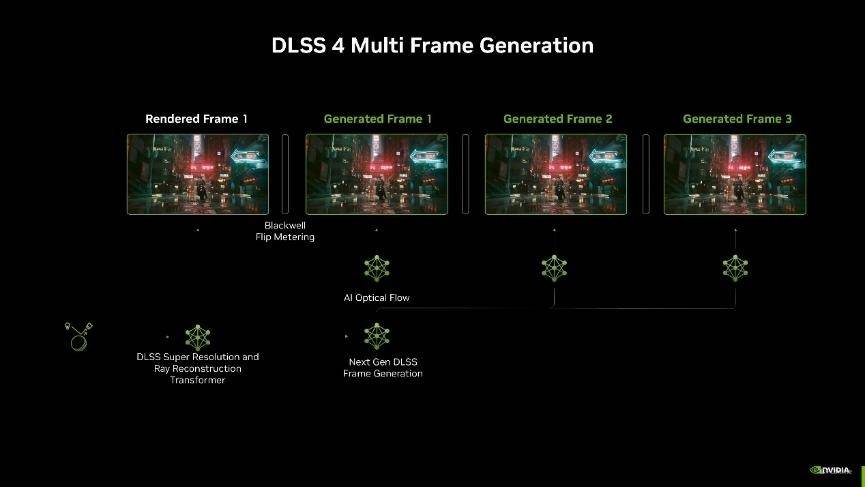
DLSS多帧生成技术还会与 DLSS 光线重建和DLSS超分辨率等其他技术协同工作。光线重建技术可以根据生成的多帧更好地处理光线追踪效果,使光线效果更加逼真和自然;超分辨率技术则可以在多帧生成的基础上,进一步提升画面的分辨率和细节,确保在高帧率下画面质量也能保持较高水平。
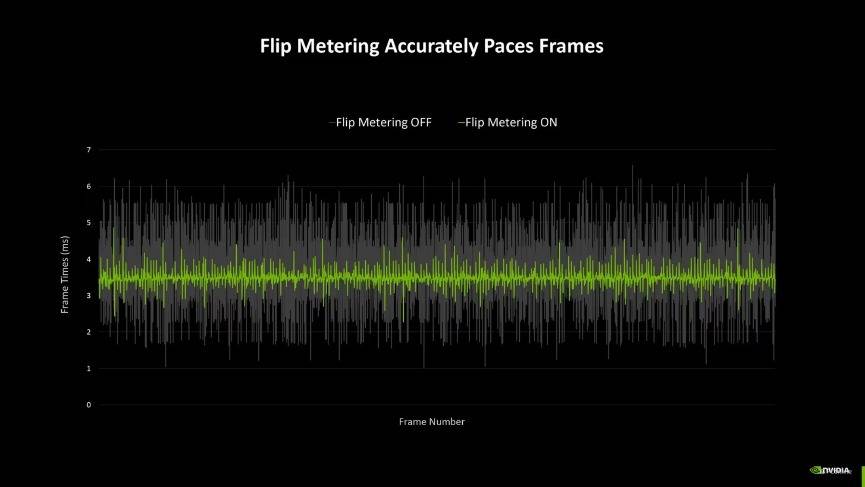
另外,由于多帧生成技术,输出的帧多了,要给每一帧都安排一个合理的间隔刷新才能让观感更好。因此NVIDIA还引入了专属的Flip Metering来代替CPU Pacing,它将帧节奏逻辑转移到显示引擎,让GPU能够更精确地管理显示时间,尽可能地将每一帧画面的生成时间保持一致,从而提高整体游戏视觉的流畅感。不过由于Flip Metering是硬件级的控制器,因此DLSS 4的多帧生成目前只有RTX 50系显卡支持。
新Transformer模型架构
DLSS 4 还引入了图形行业首个 Transformer 模型实时应用。熟悉AI的应该对它很熟悉了,它在AI生成领域已经应用多年了。基于Transformer架构的 DLSS 超分辨率和光线重建模型,相比之前DLSS使用的卷积神经网络(CNN)模型来说,具备2倍的参数量和4倍的计算量。在游戏场景中,能够提供更高的稳定性、更少的拖影、更高的细节和更强的抗锯齿能力,使画面更加清晰、流畅和逼真。
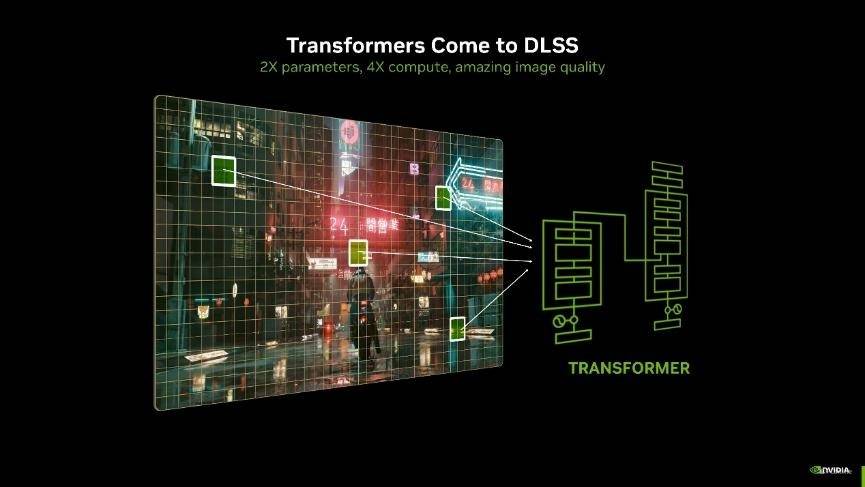
不过虽然DLSS 4的多帧生成功能是RTX 50系显卡的独占功能,但新的Transformer模型将会逐步下放至DLSS 3、DLSS 2等,将适用于所有GeForce RTX显卡。

Transformer 模型的最大优势在于其强大的全局分析能力。传统的卷积神经网络(CNN)在单帧优化上表现出色,但对动态场景中的复杂变化(如快速移动物体或光线变化)处理有限。而 Transformer 能够捕捉多帧之间的时间关系和全局场景信息,从而更加精准地还原细节,进一步减少“拖影”现象。

显存占用优化
同时得益于多帧生成功能是利用效率极高的AI模型,相较于上一代的硬件光流器进行帧生成的方式,能够显著降低生成额外帧的计算开销。反映在显示中就是能够节约显存占用,例如在《战锤 40 K:暗潮 》中,以4K最高设置游玩,DLSS 4不仅可将帧率再提升10%,还能将内存占用量减少400 MB。

超过75款游戏和应用将支持DLSS 4
超过75款游戏和应用将在GeForce RTX 50系列开售时支持DLSS 4的全新DLSS多帧生成功能,包括《赛博朋克2077》《战神:诸神黄昏》《心灵杀手2》《霍格沃兹之遗》等,《黑神话:悟空》也将于今年晚些时候升级支持 DLSS4的多帧生成。随着时间的推移,支持DLSS 4的游戏和应用数量将不断增加。

对于尚未完成更新至最新DLSS模型和功能的游戏,NVIDIA App将通过全新DLSS优设功能实现相关支持。说人话就是,如果你想玩的游戏还没有提供DLSS,你可以通过NVIDIA App进行设置,强开DLSS技术,同时随着Game Ready驱动的不断更新,DLSS相关的AI模型也会封装在驱动之中,随着模型的不断迭代,画质与性能也会越来越好,简单地说DLSS越用越好用!
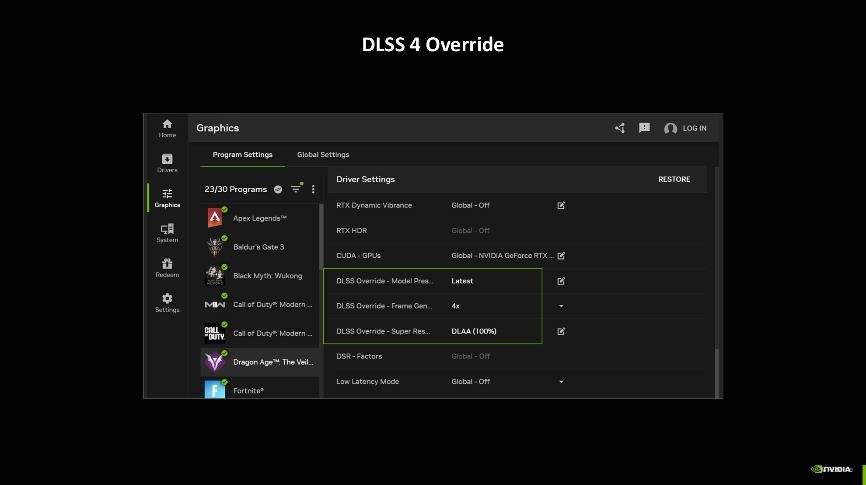
不过DLSS 4技术中的多帧生成功能目前仅支持最新的GeForce RTX 50系列显卡。究其原因还是因为多帧生成需要Blackwell架构内置的Flip Metering硬件及其他支持。因此想要体验最新的黑科技,还需要玩家更新至GeForce RTX 50系列显卡才行。

技术解析:NVIDIA Reflex 2
另外,值得一提的是,与DLSS 4一起到来的还有全新的NVIDIA Reflex 2技术。延迟一直是电竞中绕不开的话题,玩家的每个动作都会经过复杂的计算,再在屏幕上渲染,其中的每一步都会增加延迟。虽然延迟往往只有几十毫秒,但是你却能明显地感觉到游戏的不流畅、卡顿。
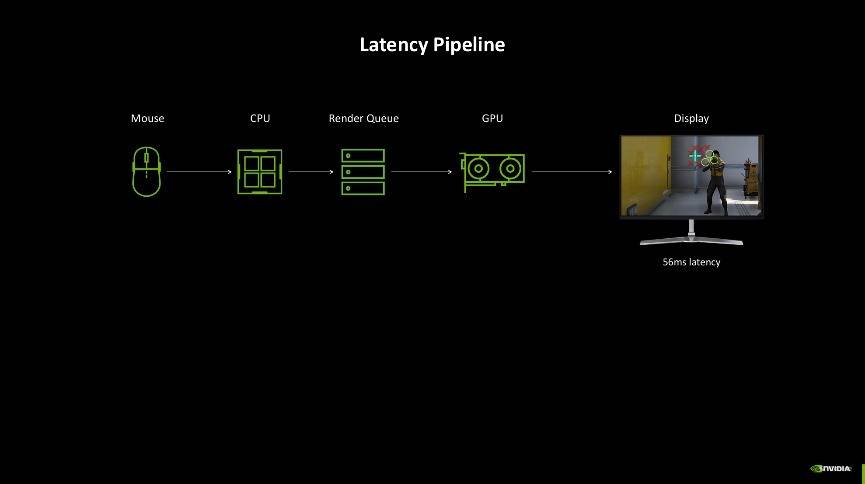
为了尽可能地降低延迟所带来的不良游戏体验,NVIDIA发布了NVIDIA Reflex技术,它可以使GPU和CPU同步,确保最佳响应速度和低系统延迟。目前NVIDIA Reflex已集成到超过100款游戏中,可以将PC延迟降低50%。

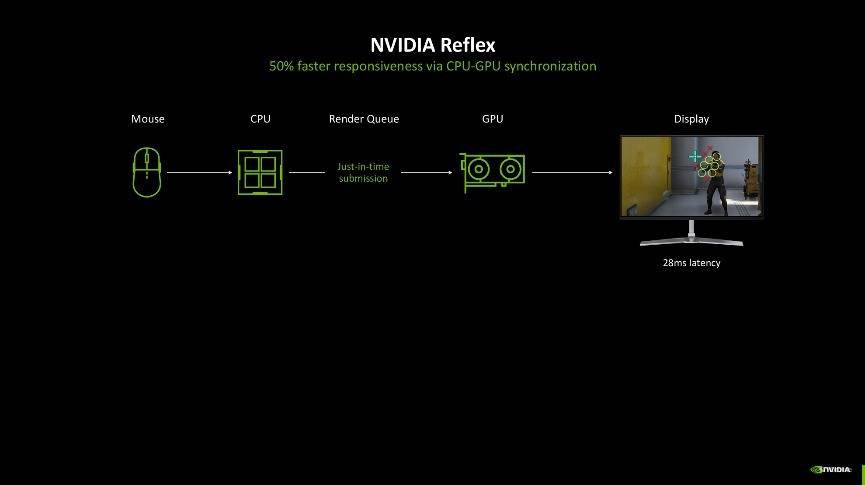
而GeForce RTX 50系显卡再度升级,带来了NVIDIA Reflex 2技术。它结合了Reflex低延迟模式与Frame Warp技术。它可以把最新的鼠标输入指令同步给渲染帧,及时更新渲染的游戏帧并在渲染帧被发送到显示器之前获取最新的鼠标信息,通过刷新渲染的游戏帧以进一步减少延迟,将PC延迟进一步降低多达75%。
另外,Frame Warp的加入,能够进一步将延迟降低。当一个帧被GPU渲染时,CPU会根据最新鼠标或手柄输入计算工作流中下一帧的视角位置。Frame Warp从CPU采样新的视角位置,然后将GPU刚才渲染的帧扭转到最新的视角位置。在渲染帧被发送到显示器之前,在尽可能最新的时间进行扭转操作,确保屏幕上反映最新鼠标输入。
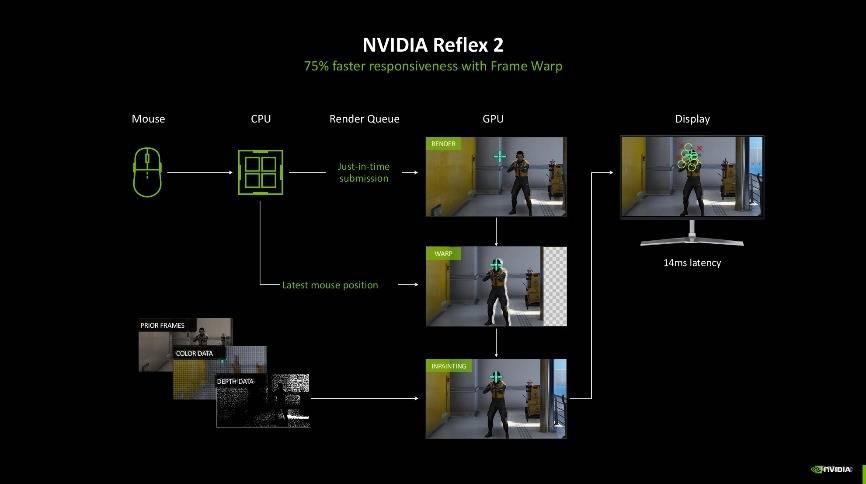
而当Frame Warp转移游戏像素时,图像中可能会产生缝隙撕裂、镜头位置的变化会让游戏场景中显示新的部分。NVIDIA则开发了一种优化了延迟的预测渲染算法,该算法使用来自先前帧的视角、颜色和深度数据,对这些撕裂空白的像素进行准确的图像修复。玩家可以通过更新的视角看到没有撕裂的渲染帧,并降低了改变游戏内视角位置而产生的延迟。说人话就是现在NVIDIA Reflex 2还可以根据上一帧的信息去脑补一些空白的像素,有种无中生有但你又看不出来的感觉。
首发支持NVIDIA Reflex 2技术的游戏是《THE FINALS》以及《无畏契约》,该技术也将在 GeForce RTX 50 系列 GPU 上首次亮相,当然后续也会逐步开放给更多的GeForce RTX系列显卡,老玩家也可以体验到最新的技术。