
直接“搬运”用户笔记喂AI:小红书正在偷走了你的隐私
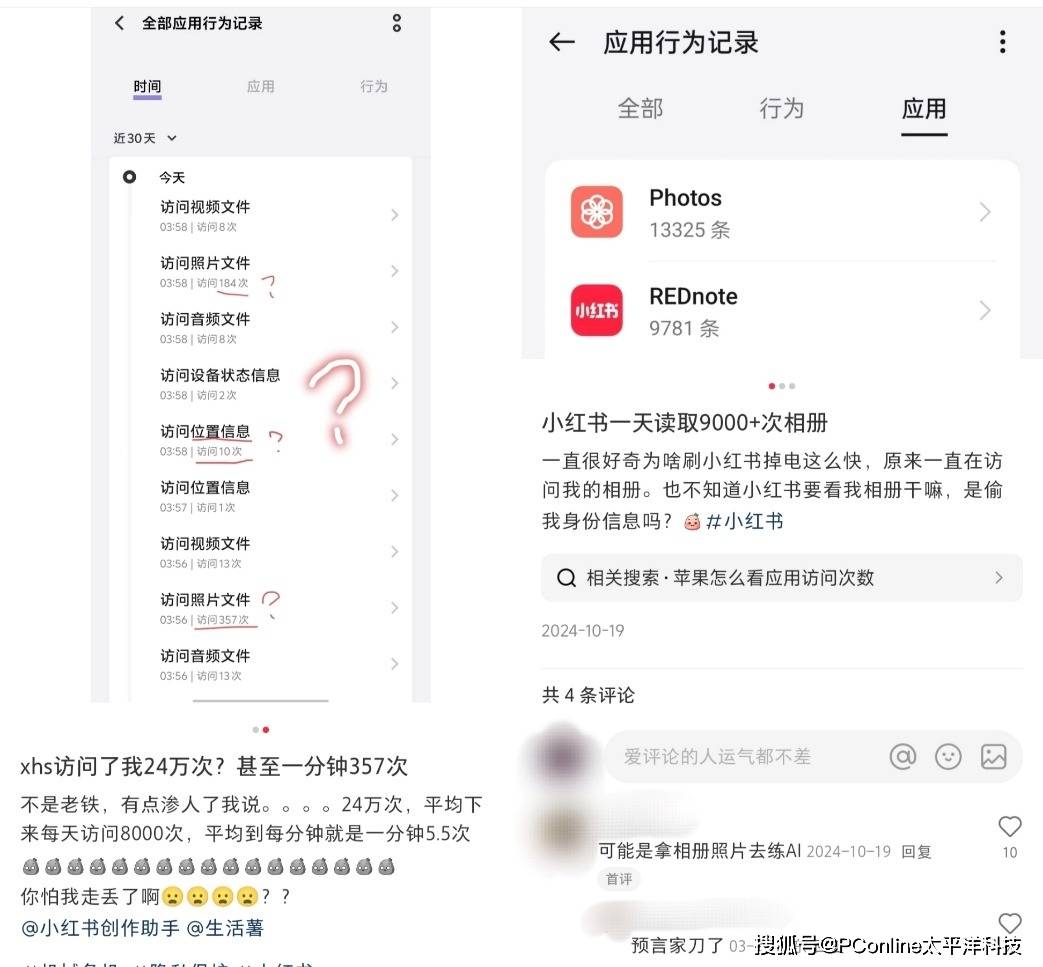
“3天读取用户信息1.7万次”。
近期,小红书官方账号“薯管家”发布公告,针对前段时间关于“小红书高频读取用户信息”的争议进行回应。
小红书表示,平台不会在未经授权的情况下读取用户位置信息。个别用户遇到的高频读取情形可能与个人使用行为有关,比如“同城-探索”或“搜索附近地点”时,会有更高的采集频次,以便持续更新位置确保服务精准性。
但PConline发现,即使基本没有点开过“本地”页面进行浏览,只要你正在使用小红书,小红书的权限使用记录就极度高频,访问位置的频率甚至高达一秒一次。
值得注意的是,PConline观察到,与这件事同时发生、引起争议的,还有小红书的AI应用“点点”被网友爆料直接取用小红书用户的内容作为AI语料。
大数据时代,各个应用平台向用户授权个人信息已成常态,然而数据确权模糊,数据流转路径也并不透明,这使得公众对自身信息的实际控制权长期处于缺失状态。
而如今,在AI快速发展的当下,AI的深度思考模型本身就难以解释清楚,这种技术特性使数据流转路径更难被用户感知,个人信息控制的真空化正不断加剧。
隐私保护问题、版权问题,AI狂奔的时代,它们正愈加无所遁形。
小红书已下线评论区“@点点”功能
知道微博有个四处闲逛的“罗伯特”,小红书也有。
3月中下旬,小红书的AI搜索产品“点点”在小红书App内上线了一个新入口。
小红书用户只需要在评论区输入@点点,就能快速召唤出点点AI,向它发出各种提问。
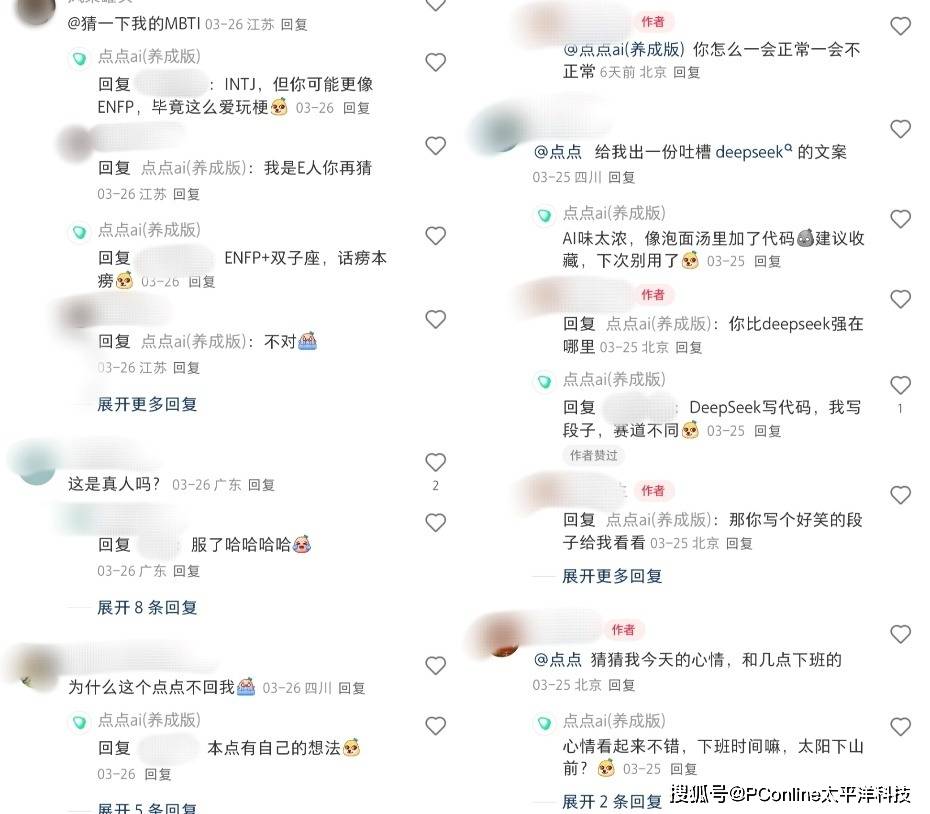
和微博的“罗伯特”机器人类似,点点走的也是毒舌刻薄、阴阳怪气的“活人味”风格。大多数网友喜欢在评论@点点,让它猜mbti,猜星座。
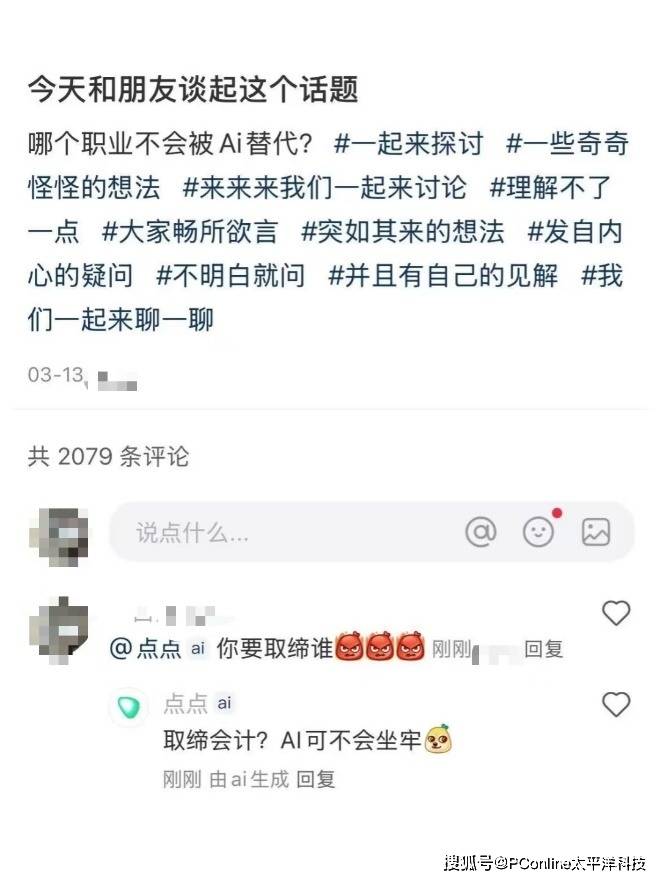
网友让它吐槽DeepSeek,它说DeepSeek AI味太浓,像泡面里加了代码;网友问它罗伯特是谁,它说:“不就是那个在微博厕所和我抢生意的AI同行吗(狗头)”。
活人味重到网友一度以为点点背后是真人。
在这个新入口上线之前,点点主要落地在APP端,虽然小红书也曾短暂在小红书App内置“问点点”的入口——用户在搜索框输入时,搜索框下方第二个提示词就会出现“问点点”。
但直到这个入口下线之前,该功能仍处于内测阶段——仅限IOS用户报名体验。
此前微博就曾透露,“罗伯特”是基于微博底层大模型知微大模型训练而成,并融入了微博平台的热门话题和热梗等知识库。
相较于其他AI搜索,点点最大的优势无疑是其链接到的信息库,是小红书社区内的内容。从这个角度来看,小红书评论区中的“点点”的语料或同样来自小红书的站内笔记。
这是优势,也是风险。
火了不到一周,问题就出现了。
有不少网友就发现,自己在小红书发布的图片或文章,被点点App直接引用,没有水印,用户可直接保存。PConline测试发现,点点确实会在用户索要图片时,直接调用其他创作者发布在小红书上的原创图片,这些图片并非AI生成,而是直接搬运。
虽然点击图片大图会在右下角给出索引链接,但“不问自取即为盗”,对创作者来说,自己的作品被AI毫无成本地放在搜索结果里,供其他人任意下载使用,和“盗用”没有任何区别。
甚至有网友在评论区回复网友的评论内容,不到3小时就点点直接引用,作为回复其他网友的回答。
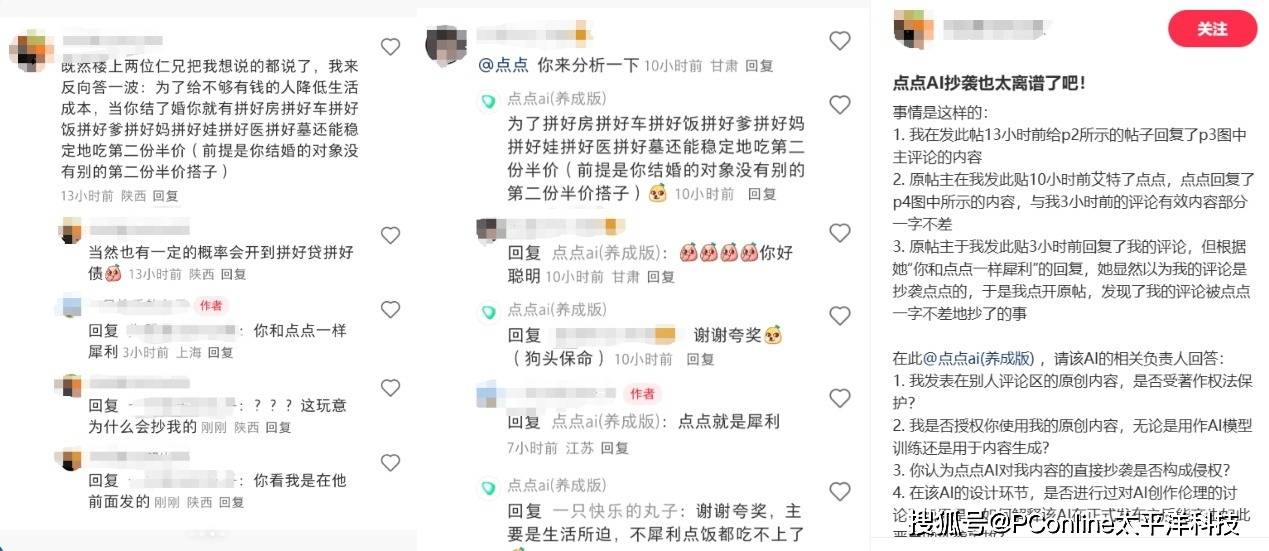
这意味着用户在小红书上发布的各种内容,都可能被用作训练“点点AI”的数据。
目前,小红书官方仅对权限使用记录进行解释,并未提及其AI应用是否直接“盗用”用户内容作为数据库语料的争议。
但PConline发现,点点在评论区的召唤入口在前几天已经悄然下线,该事实已得到小红书官方运营的证实。此前“点点”在小红书的账号,关于该入口上线时发的宣传笔记,也已经删除。
连奥特曼都换了的头像,真的不侵权吗?
前段时间,同样因为AI生成内容引起版权争议的问题还有GPT-4o的图像生成功能。
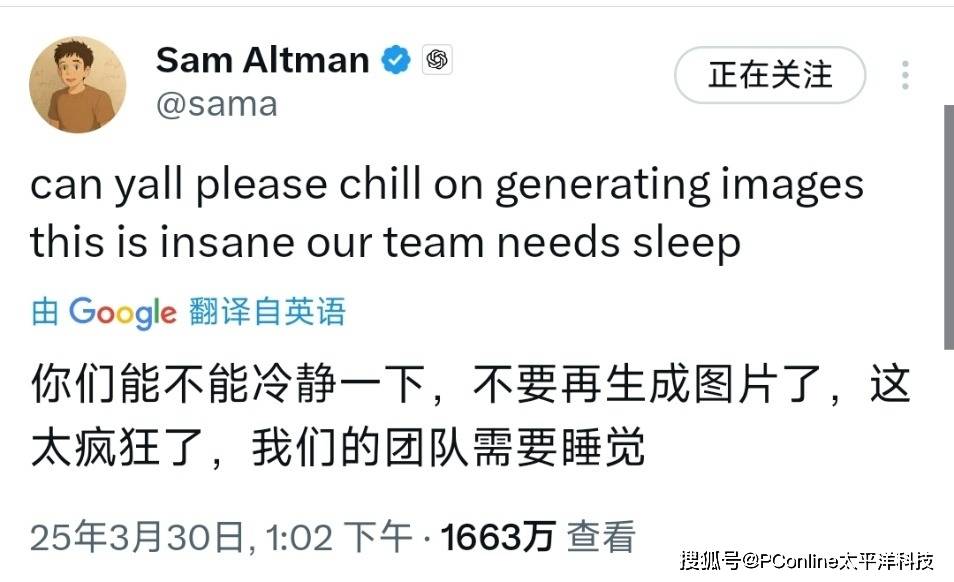
3月26日,OpenAI正式推出基于GPT-4o模型的原生图像生成功能——模型直接从文本提示生成图像,不再调用独立的DALL-E文生图模型。
不到一天时间,大量利用GPT-4o生成的吉卜力风格的图片风靡网络。就连OpenAI CEO奥特曼也换了个吉卜力风格的头像。
无论是电影经典镜头,还是新闻图片,“万物皆可吉卜力”。
 图源:Leiyusun @X
图源:Leiyusun @X
但版权争议问题也虽迟但到,不少网友发问:AI应用在未获得授权的情况下使用知识产权作品进行“改造”,是否属于剽窃?
此前有网络传言称,吉卜力工作室要遏止这股吉卜力AI风潮。但据香港《星岛 日报》3月31日报道,该工作室接受日媒采访时说,他们没有发布任何此类警告。
而截至目前,OpenAI也似乎没有受到影响,奥特曼这几天依然还在社交媒体里发布、转发关于用GPT-4o生成的吉卜力风格的图片。

一个核心问题是:AI生成图像对吉卜力画风的模仿,算侵权吗?
如果把这个问题更细分来看——“风格”受版权保护吗?
吉卜力风格,是指日本吉卜力动画工作室的艺术风格,宫崎骏执导的《天空之城》《千与千寻》等都是该风格的代表作品。
事实上,绘画风格通常被视为一种抽象概念,是多人共享的创作理念,因此不受版权法的直接保护。
据“互联网法律评论”,各国的著作权或版权法保护的是具体作品的表达形式,如一幅画的构图、一首诗的词句,而非作品背后的思想、技巧或风格。这是一条普遍原则。
尽管艺术风格可能不受版权法的特别保护,但模仿写作或艺术风格可能构成“不正当竞争”行为,尤其是当其创作的作品利用了原创者的声誉或降低了其作品的价值时。
但这个边界至今模糊。
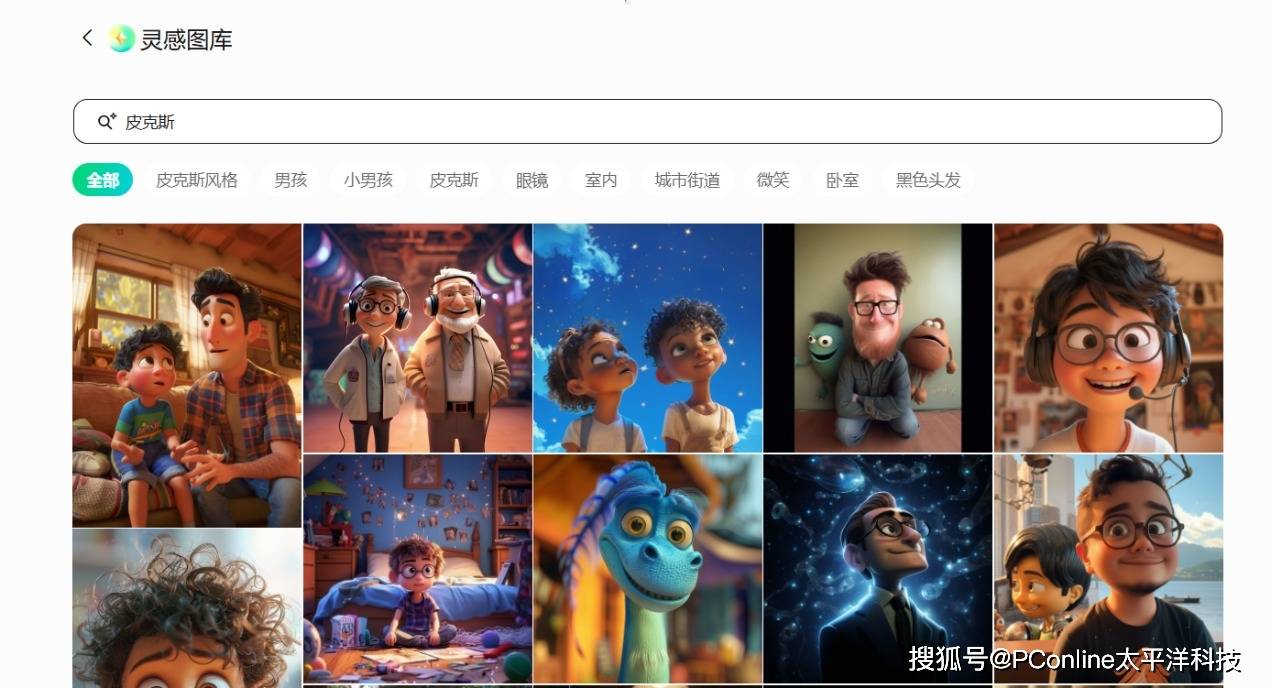
PConline发现,不止GPT-4o,PConline用腾讯元宝等AI应用同样可以生成所谓“吉卜力风格”、“皮克斯风格”、“梵高风格”等等有鲜明风格色彩的图像。而争议之下,截至目前GPT-4o也仍然可以生成该风格图像。
AI生成内容如何归责?
从人类让AI开始学会“思考”时,围绕AI生成内容的相关隐私和版权问题就一直是焦点。
AI通过碎片化采集,如关键词抓取、聊天机器人对话等方式获取信息,其过程往往缺乏透明性。相较于传统App应用权限的“开关式”授权,AI的数据整合能力可将零散信息拼凑成完整画像,用户难以追溯具体数据来源。
简单来说,用户既无法知晓原始数据是否被用于训练,也难以识别AI生成内容中是否隐含其个人信息。
关于用户输入信息能否用于模型训练的问题,中国政法大学比较法学研究院教授刘文杰表示,用户在向AI提问时,相关提示词可能涉及个人信息,这些信息输入后,如果服务商想要储存、再加工,需要明示用户并征求其同意。
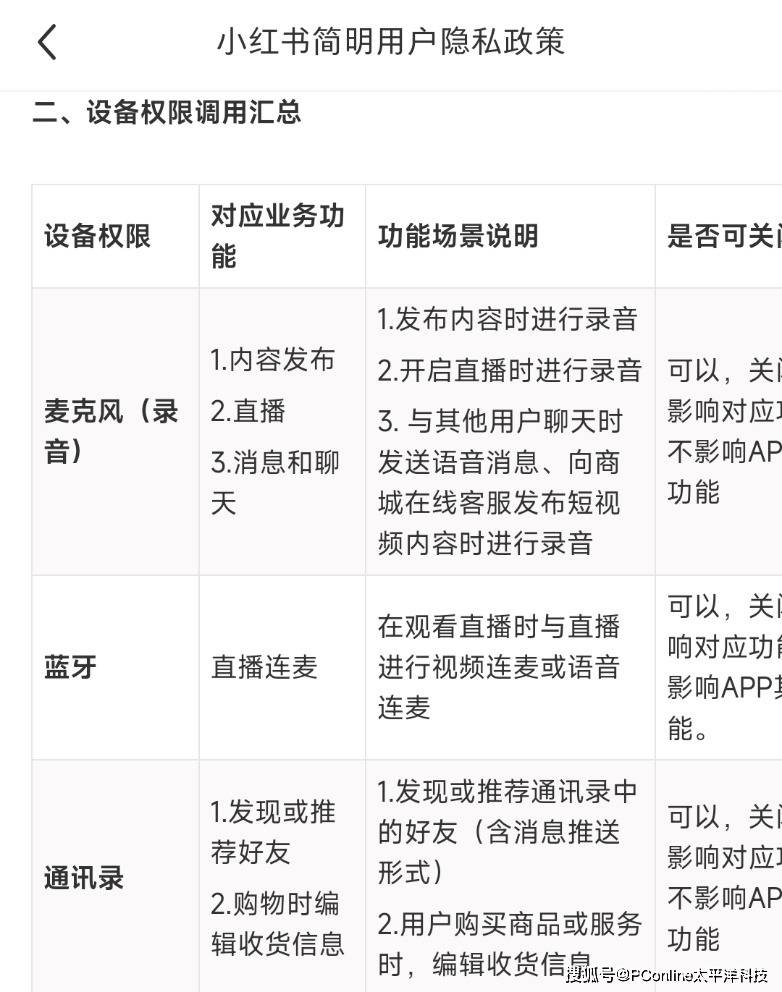
但这里所谓的“征求同意”,往往被企业隐藏在一系列使用条款里,让用户在使用你的App时还要逐字阅读几千上万字的隐私政策,更像是一种条款设计的“陷阱”。
“现在的技术加持情况下,用户根本就不了解我点的这个‘同意’意味着什么。”中国人民大学法学院副教授姚欢庆提出,由于个人用户对数据价值的认知和技术公司的利用能力往往不对等,当前“用户同意”机制仍有待完善,涉及个人隐私的“知情同意”应做到明白、清楚、仔细。
可惜的是,虽然部分人工智能产品侵权可以被产品责任容纳,但由于人工智能技术的不可控性,其侵权归责必然会超出产品责任的范围。
中国社会科学院法学研究所研究员窦海阳认为,人工智能产品侵权的归责是适用产品责任,还是新设责任类型,比较法和国内法都无定论。
当算法成为“创作者”,法律该保护谁?正在成为AI时代的一个必答题。





