DeepSeek低调升级却引爆AI圈!又一次超越OpenAI
没有发布会,没有新闻稿,甚至连更新说明都没有,但全球AI开发者在凌晨两点的下载中见证了中国开源大模型的又一次进化。
与OpenAI、Anthropic等公司大张旗鼓的发布风格截然相反,DeepSeek此次更新延续了其一贯的技术极客作风。在微信群简短通知后,工程师团队在29日凌晨将模型上传至HuggingFace,连模型卡都未更新就转身离开。
这种低调几乎成为DeepSeek的独特标签。今年3月更新V3模型时,团队同样“默默上新”,直到开发者自行测试才发现其性能已全面超越Claude 3.7 Sonnet。
“版本号只是营销需求”,一位业内人士猜测,DeepSeek可能认为只要模型架构不变,就不算大版本升级。这种务实态度背后,是中国团队对技术实质而非宣传声量的专注。
沉默的发布,轰鸣的性能
尽管官方未提供任何性能说明,全球开发者社区在24小时内自发完成了对新模型的全面“体检”。测试结果令人震惊:
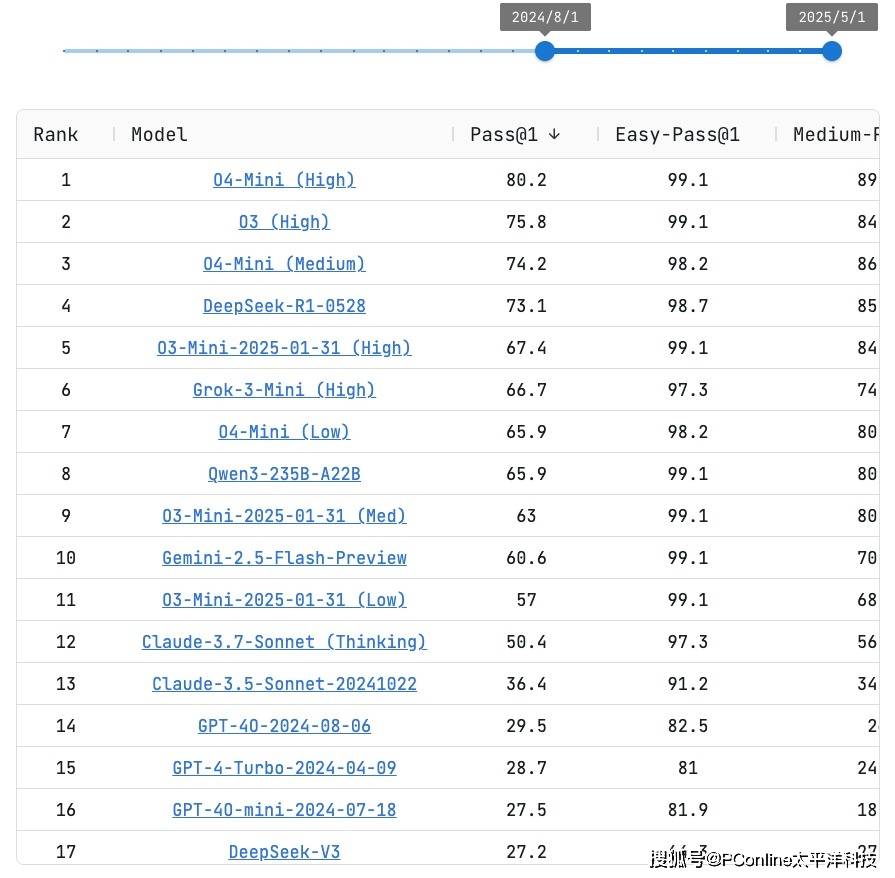
在权威编程评测平台Live CodeBench上,DeepSeek-R1-0528得分紧咬OpenAI o4-Mini(Medium),排名第四。要知道,这几个都是Open AI旗下的高性能商业模型,而DeepSeek-R1-0528不仅性能和他们接近,最重要的是开源、免费!
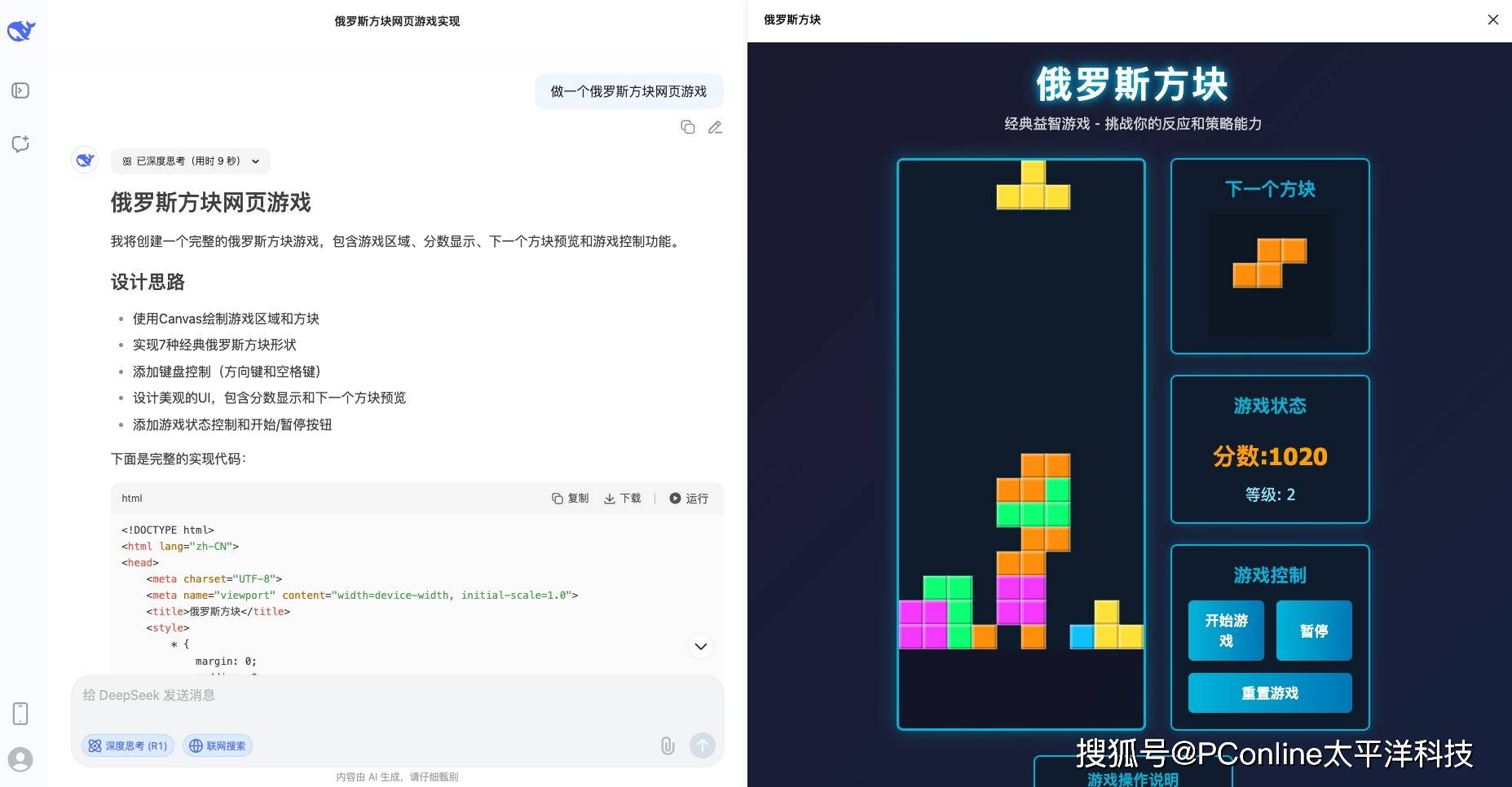
我们试着让它写一个俄罗斯方块网页游戏,思考9秒后它就开干了,一次性写完所有代码,并且可以直接在网页上运行。仔细玩了2分钟,没有任何问题,界面设计也挺好,感觉有事没事就能写个游戏消磨时光了。
代码能力之外,新模型在其他维度同样取得显著进步:
写作风格正常化:早期版本中用户诟病的“量子力学式表达”——即过度使用专业术语的问题明显改善,输出更自然流畅;
结构化思维增强:在解决复杂问题时,R1展现出更清晰的思维链条,逻辑推进更严密,被开发者描述为“像谷歌模型一样深度推理”;
长文本处理优化:在32K上下文长度内,文本召回准确率明显提升;但超过60K时性能有所下降,显示长上下文稳定性仍需加强;
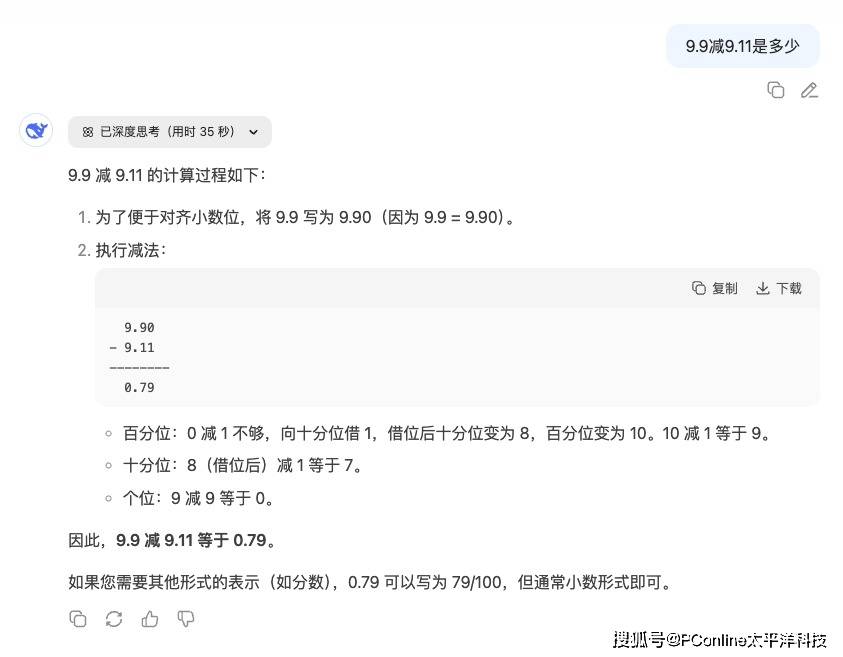
最引人注目的是新增的长时思考能力。新R1单任务处理时间可达30-60分钟,有用户实测遇到模型“长考”212秒才给出答案,远超之前版本。这种深度思考机制使其成为目前唯一能持续正确回答“9.9减9.11是多少”的模型。
R2会有多强?
“如果R1小升级就如此惊艳,R2会有多强?” 海外网友的疑问道出整个AI社区的心声。在社交媒体上,每条关于R1升级的讨论下都充斥着对R2的询问。
爆料显示,传说中的R2可能是真正的“大杀器”:采用混合专家模型(MoE)架构,参数量达1.2万亿,较R1提升80%,推理成本暴降,性价比突破想象,芯片利用率高达82%。

更值得玩味的是技术路线——4月DeepSeek与清华大学联合发布《自我原则点评调优》(SPCT)论文,提出元奖励模型(meta RM)新方法,被视为R2的技术前兆。
低调背后的行业变革逻辑
DeepSeek的“小版本大升级”策略揭示了中国AI团队独特的发展哲学:不重版本号,只重实际能力提升
当商业公司热衷通过版本迭代制造营销热点时,DeepSeek选择将资源投入到实质性能突破上。今年3月的V3更新借鉴R1的强化学习技术提升推理能力,却仅定义为小版本升级。

这种务实精神带来惊人性价比。DeepSeek-V3-0324的输入成本仅为Claude Sonnet 3.7的1/11,GPT-4.5的1/277。而新R1作为开源模型,其性能却直逼天价商业产品。
“开源的巨大胜利”,开发者的评价点明此次升级的深层意义。当顶级AI能力不再被封闭在商业公司的黑箱中,而是通过开源社区自由流通,整个行业的创新速度将呈指数级提升。
当全球开发者都在问“R2何时来”时,DeepSeek已用行动作答:最好的预告片,永远是今天的代码。