
罗福莉掌舵小米AI:发布MiMO大模型 剑指通用智能
在12 月 17 日开幕的2025小米人车家全生态合作伙伴大会上,备受瞩目的小米大模型团队迎来了新任掌门人的首次公开亮相。作为Xiaomi MiMO大模型负责人,罗福莉并没有选择常规的客套寒暄,而是直接抛出了一枚技术重磅炸弹——正式发布最新一代MoE(混合专家)大模型MiMo-V2-Flash。对于这一里程碑式的发布,相关负责人将其定义为小米在通往人工通用智能(AGI)宏伟蓝图中的关键第二步,标志着小米在顶级模型研发领域已从跟随迈向了引领。
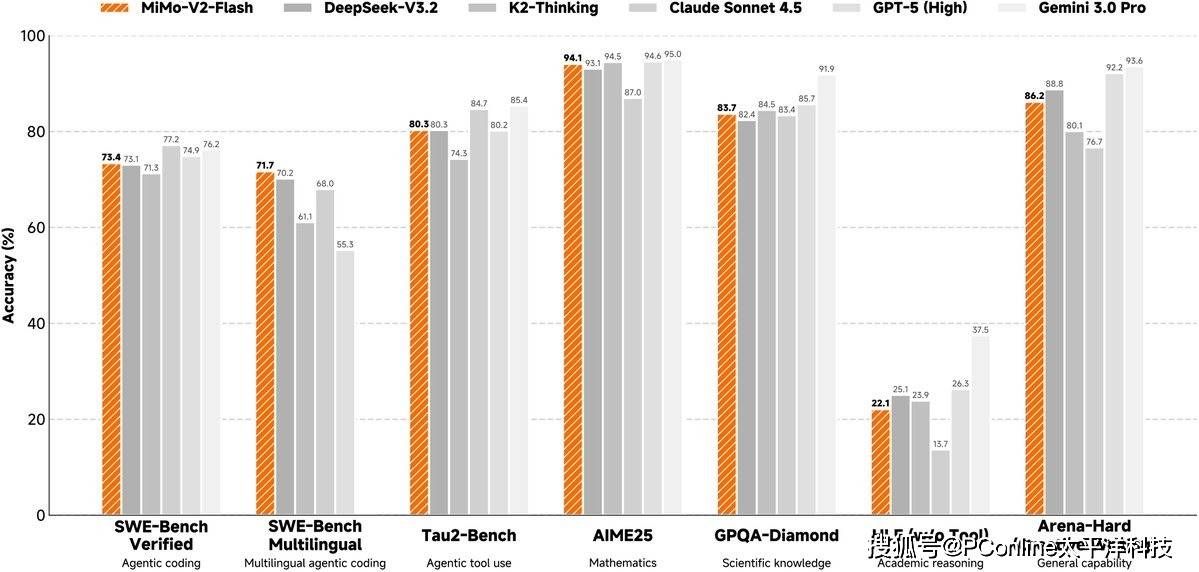
在随后的技术深度解析环节,有关方面披露了MiMo-V2-Flash背后的硬核架构细节,展现了小米团队在平衡模型性能与算力效率上的独特思考。据悉,该模型并未盲目堆砌参数,而是采用了一种名为Hybrid SWA的混合架构。这种设计被业内评价为极具极简主义美学,既摒弃了繁复的冗余结构,又在长文本推理能力上实现了对传统线性注意力变体的显著超越。
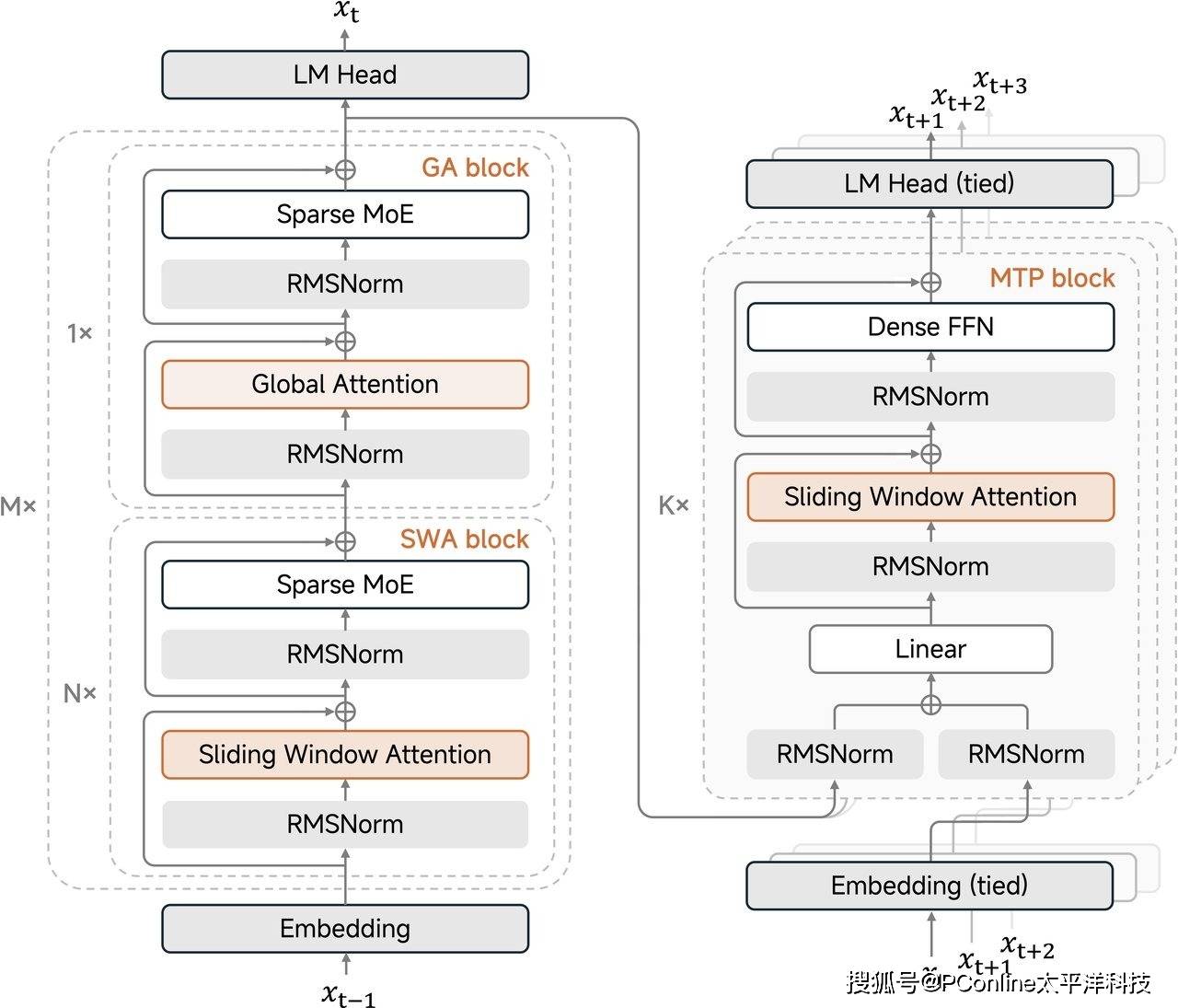
特别值得关注的是,技术团队在研发过程中发现了一个颇为反直觉的现象:窗口大小并非越大越好。经过反复验证,128被确定为最佳的窗口大小设定,一旦超过这个阈值,模型的综合性能反而会出现下滑。这一发现不仅为行业提供了新的调优思路,配合固定的KV缓存设计,更是极大地提升了新模型与现有计算基础设施的兼容性,为大规模快速部署扫清了障碍。
除了架构层面的革新,罗福莉还着重介绍了多标记预测(MTP)技术的应用。这项技术被视为此次性能飞跃的另一大引擎,特别是在强化学习(RL)的高效化方面效果卓著。有别于传统模型逐个预测下一个token的低效模式,MTP技术允许模型在预测时看得更远。数据表明,即便仅在第一层之外进行少量的微调,MTP也能帮助模型获得极高的接受长度。
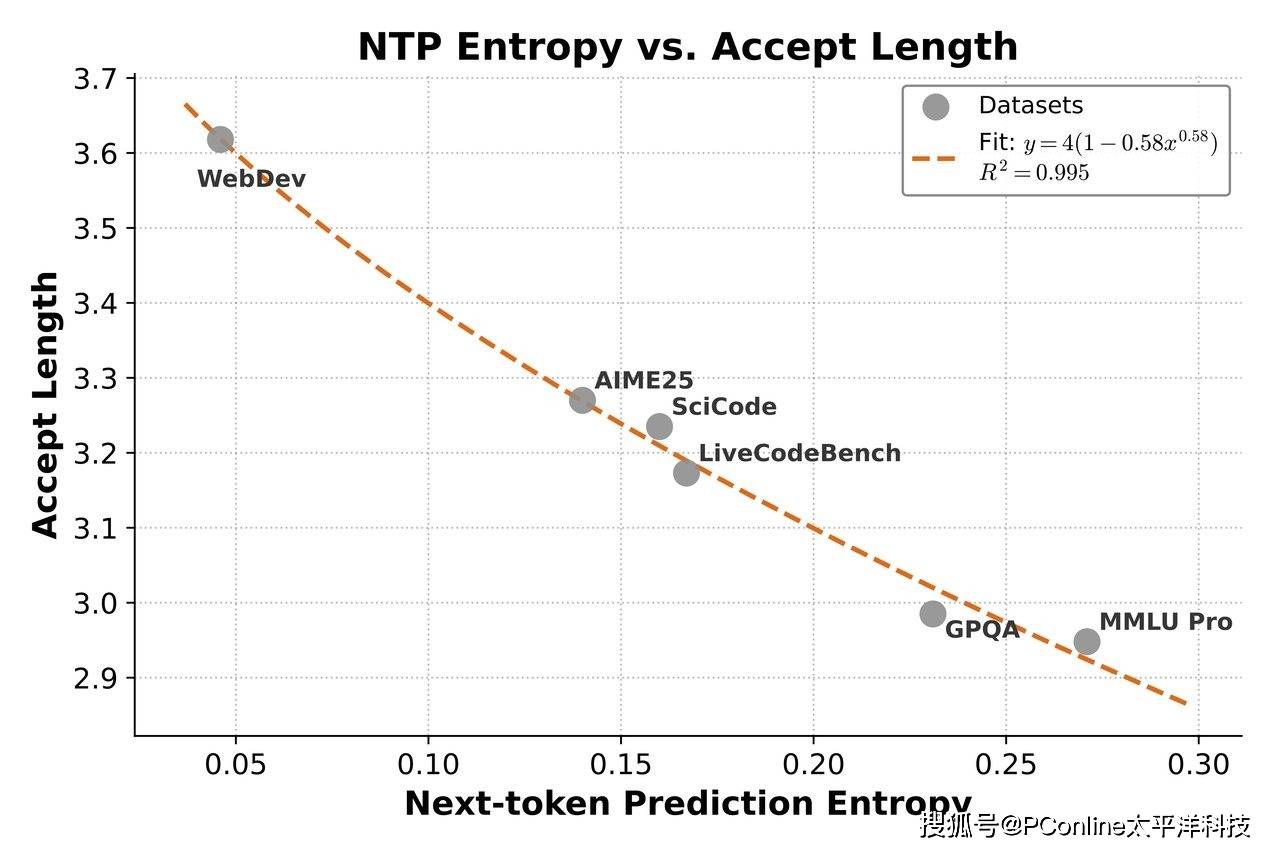
在具体的编程任务测试中,三层MTP架构的表现尤为抢眼,不仅实现了大于3的接受长度,更将推理速度提升了约2.5倍。这一改进直击当前AI训练的痛点,有效解决了在小批量On-Policy强化学习过程中常见的GPU空转问题,让昂贵的算力资源得到了最大化利用。
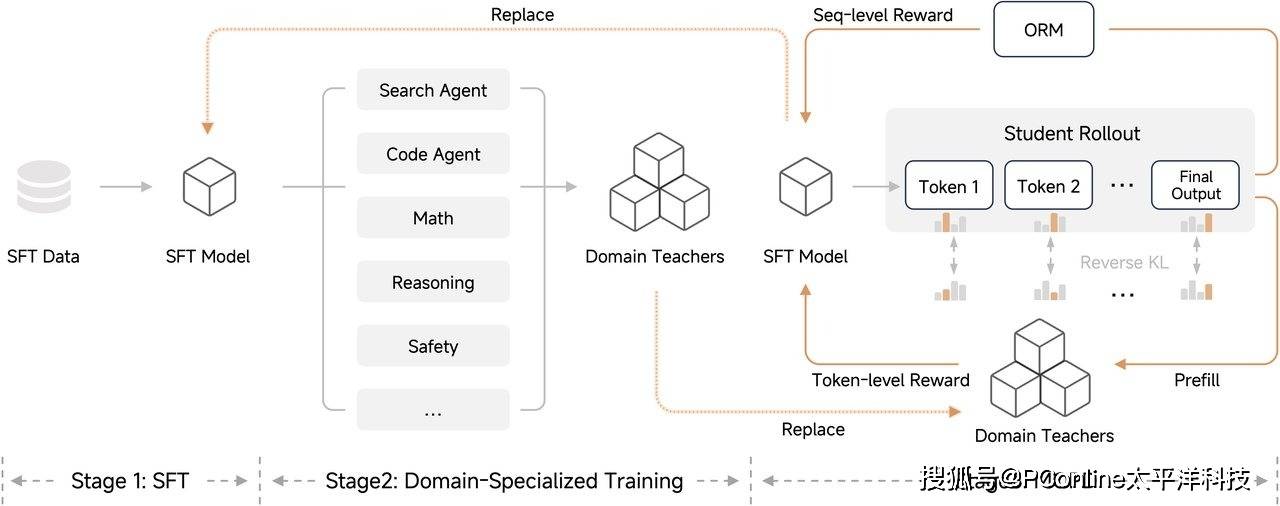
在后训练阶段,小米团队展现了极强的技术整合能力。据透露,团队采纳了Thinking Machine提出的On-Policy Distillation(在线策略蒸馏)方案,旨在将多个强化学习模型的优势进行深度融合。这一策略的效果立竿见影:小米成功在传统的监督微调(SFT)和强化学习流程中,以仅仅相当于教师模型五十分之一的计算量,达到了同等水平的性能表现。这种四两拨千斤的方法,展示了学生模型在不断迭代中具备的惊人进化潜力,最终形成了一个自我增强、自我完善的良性闭环。
回顾整个研发历程,相关负责人感慨团队展现出的非凡战力。从理论构想到转化为可上线运行的生产级系统,小米AI团队仅用了短短几个月时间。这种高效与创造力,不仅是小米技术实力的体现,更为其在激烈的人车家全生态竞争中构筑了坚实的护城河。





